Chapter 2 Introduction to ANOVA and Linear Regression
This Chapter aims to answer the following questions:
What is a predictive model versus an explanatory model?
How to perform an honest assessment of a model.
How to estimate associations.
- Continuous-Continuous
- Continuous-Categorical
- Pearson’s correlation
- Test of Hypothesis
- Effect of outliers
- Correlation Matrix
How to perform ANOVA.
- Testing assumptions
- Kruskal-Wallis
- Post-hoc tests
How to perform Simple Linear Regression.
- Assumptions
- Inference
In this chapter, we introduce one of the most commonly used tools in data science: the linear model. We’ll start with some basic terminology. A linear model is an equation that typically takes the form \[\begin{equation} \mathbf{y} = \beta_0 + \beta_1\mathbf{x_1} + \dots + \beta_k\mathbf{x_k} + \boldsymbol \varepsilon \tag{2.1} \end{equation}\]
The left-hand side of this equation, \(\mathbf{y}\) is equivalently called the target, response, or dependent variable. The right-hand side is a linear combination of the columns \(\{\mathbf{x_i}\}_{i=1}^{k}\) which are commonly referred to as explanatory, input, predictor, or independent variables.
2.1 Predictive vs. Explanatory
The purpose of a linear model like Equation (2.1) is generally two-fold:
- The model is predictive in that it can estimate the value of \(y\) for a given combination of the \(x\) attributes.
- The model is explanatory in that it can estimate how \(y\) changes for a unit increase in a given \(x\) attribute, holding all else constant (via the slope parameters \(\beta\)).
However, it’s common for one of these purposes to be more aligned with the specific goals of your project, and it is common to approach the building of such a model differently for each purpose.
In predictive modeling, you are most interested in how much error your model has on holdout data, that is, validation or test data. This is a notion that we introduce next in Section 2.2. If good predictions are all you want from your model, you are unlikely to care how many variables (including polynomial and interaction terms) are included in the final model.
In explanatory modeling, you foremost want a model that is simple to interpret and doesn’t have too many input variables. It’s common to avoid many polynomial and interaction terms for explanatory models. While the error rates on holdout data will still be useful reporting metrics for explanatory models, it will be more important to craft the model for ease of interpretation.
2.2 Honest Assessment
When performing predictive or explanatory modeling, we always divide our data into subsets for training, validation, and/or final testing. Because models are prone to discovering small, spurious patterns on the data that is used to create them (the training data), we set aside the validation and testing data to get a clear view of how they might perform on new data that they’ve never seen before. This is a concept that will be revisited several times throughout this text, highlighting its importance to honest assessment of models.
There is no single right answer for how this division should occur for every data set - the answer depends on a multitude of factors that are beyond the scope of our present discussion. Generally speaking, one expects to keep about 70% of the data for model training purposes, and the remaining 30% for validation and testing. These proportions may change depending on the amount of data available. If one has millions of observations, they can often get away with a much smaller proportion of training data to reduce computation time and increase confidence in validation. If one has substantially fewer observations, it may be necessary to increase the training proportion in order to build a sound model - trading validation confidence for proper training.
Below we demonstrate one technique for separating the data into just two subsets: training and test. These two subsets will suffice for our analyses in this text. We’ll use 70% of our data for the training set and the remainder for testing.
Since we are taking a random sample, each time you run this functions you will get a different result. This can be difficult for team members who wish to keep their analyses in sync. To avoid that variation of results, we can provide a “seed” to the internal random number generation process, which ensures that the randomly generated output is the same to all who use that seed.
The following code demonstrates sampling via the tidyverse. This method requires the use of an id variable. If your data set has a unique identifier built in, you may omit the first line of code (after set.seed()) and use that unique identifier in the third line.
2.2.0.1 R code:
library(tidyverse)
set.seed(123)
ames <- ames %>% mutate(id = row_number())
train <- ames %>% sample_frac(0.7)
test <- anti_join(ames, train, by = 'id')
dim(train)## [1] 2051 82## [1] 879 822.2.1 Python Code:
To create the training data set in Python
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
train,test = train_test_split(ames_py,test_size=0.3,random_state=123)
print(train.shape)## (2051, 82)## (879, 82)However, note that this will create a different train/test split. Therefore, we will just pull in our train/test data set from Python.
2.3 Bivariate EDA
As stated in Chapter 1, exploratory data analysis is the foundation of any successful data science project. As we move on to the discussion of modeling, we begin to explore bivariate relationships in our data. In doing so, we will often explore the input variables’ relationships with the target. Such exploration should only be done on the training data; we should never let insights from the validation or test data inform our decisions about modeling.
Bivariate exploratory analysis is often used to assess relationships between two variables. An association or relationship exists when the expected value of one variable changes at different levels of the other variable. A linear relationship between two continuous variables can be inferred when the general shape of a scatter plot of the two variables is a straight line.
2.3.1 Continuous-Continuous Associations
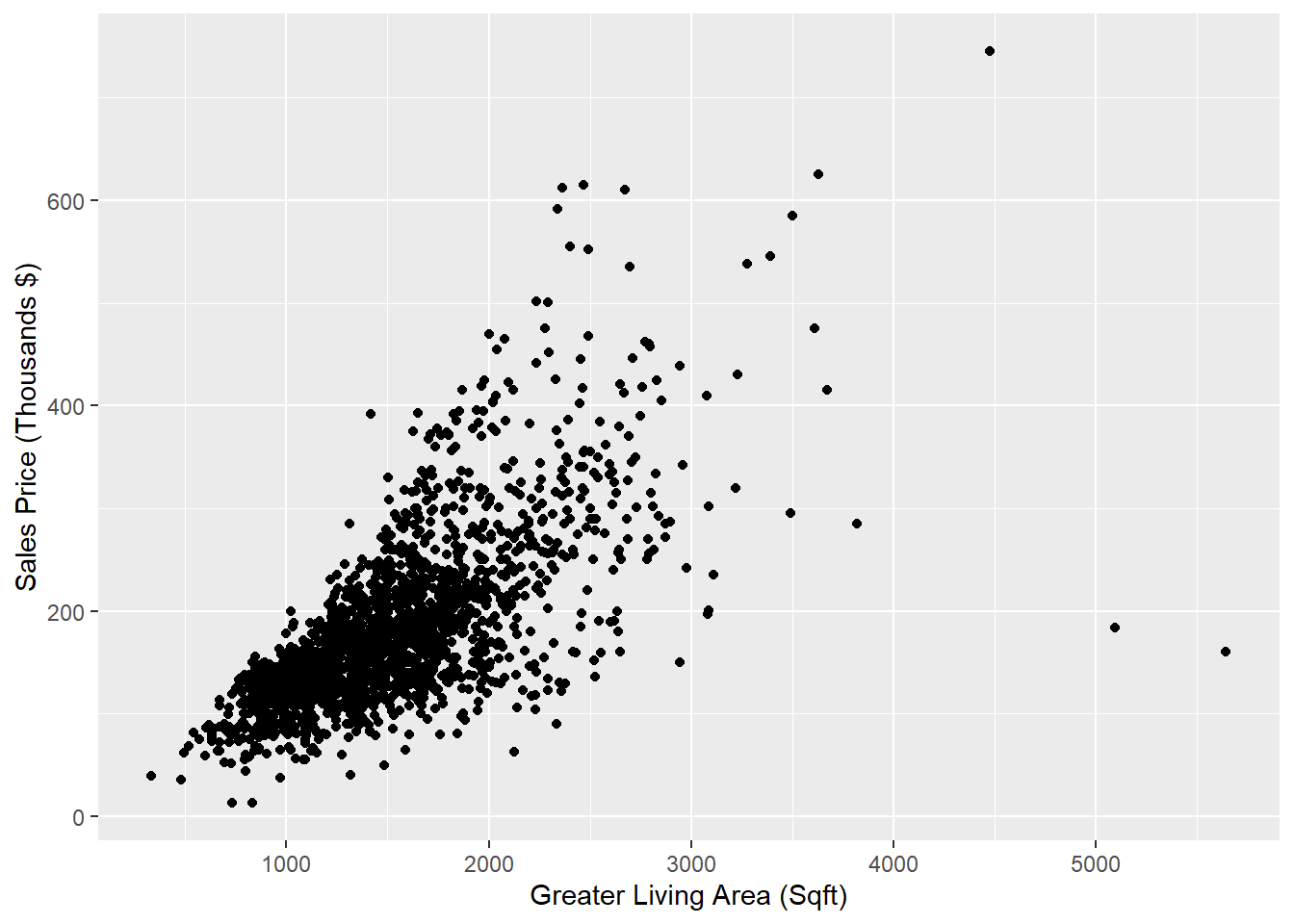
Let’s conduct a preliminary assessment of the relationship between the size of the house in square feet (via Gr_Liv_Area) and the Sale_Price by creating a scatter plot (only on the training data). Note that we call this a preliminary assessment because we should not declare a statistical relationship without a formal hypothesis test (see Section 2.6).
2.3.2 Continuous-Categorical Associations
We’ll also revisit the plots that we created in Section 1.1, this time being careful to use only our training data since our goal is eventually to use a linear model to predict Sale_Price.
We start by exploring the relationship between the external quality rating of the home (via the ordinal variable Exter_Qual and the Sale_Price).
The simplest graphic we may wish to create is a bar chart like Figure 2.2 that shows the average sale price of homes with each value of exterior quality.
ggplot(train) +
geom_bar(aes(x=Exter_Qual,y= Sale_Price),
position = "dodge", stat = "summary", fun = "mean") +
scale_y_continuous(labels = function(x) format(x, scientific = FALSE)) # Modify formatting of axis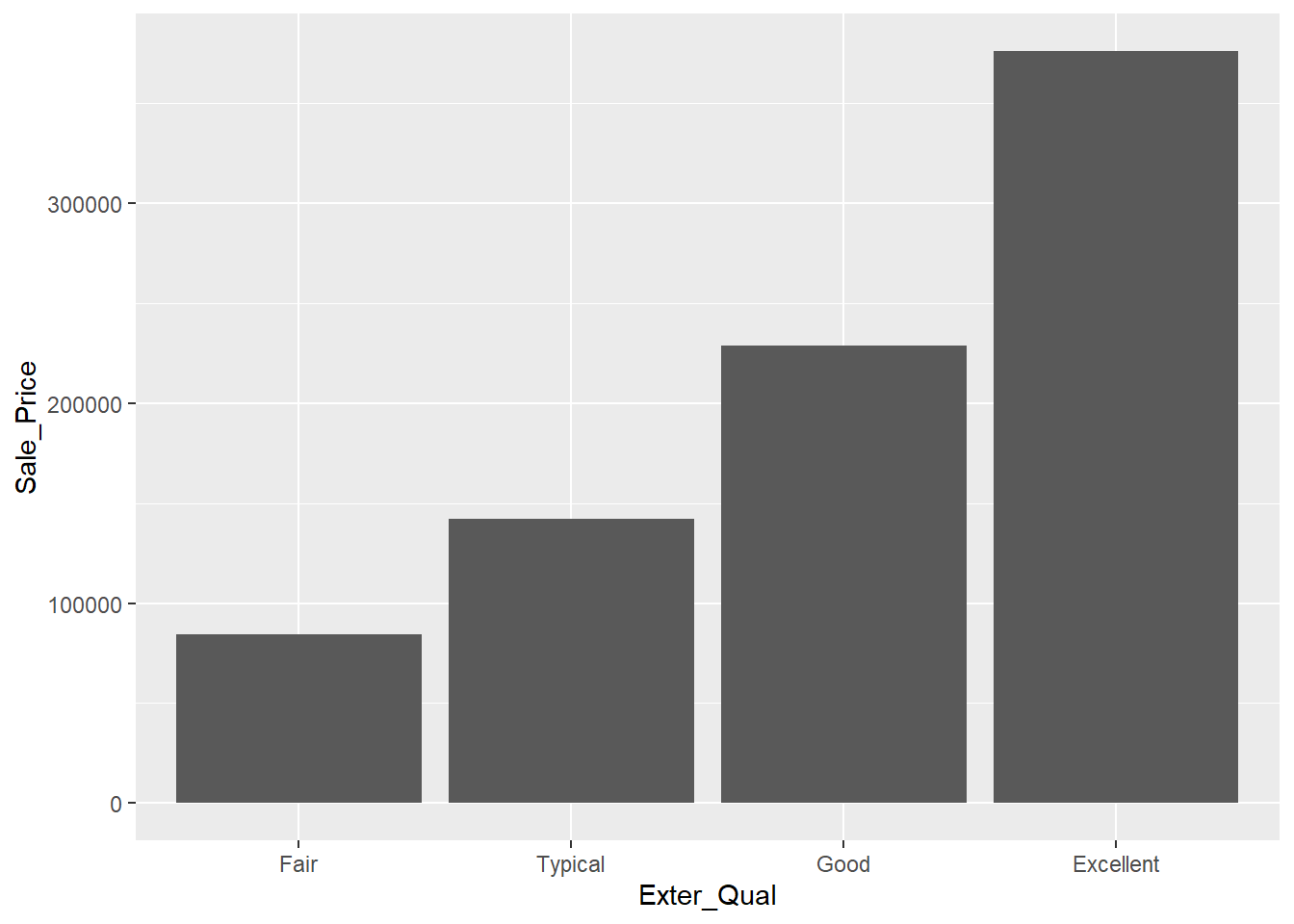
Figure 2.2: Bar Chart Comparing Average Sale Price of Homes with each Level of Exterior Quality
This gives us the idea that there may be an association between these two attributes, but it can be tricky to rely solely on this graph without exploring the overall distribution in sale price for each group. While this chart is great for the purposes of reporting (once we’ve verified the relationship), it’s not the best one for exploratory analysis. The next two charts allow us to have much more information on one graphic.
The frequency histogram in Figure 2.3 allows us to see that much fewer of the homes have a rating of Excellent versus the other tiers, a fact that makes it difficult to compare the distributions. To normalize that quantity and compare the raw probability densities, we can change our axes to density (which is analogous to percentage) and employ a kernel density estimator with the geom_density plot as shown in Figure 2.3. We can then clearly see that as the exterior quality of the home “goes up” (in the ordinal sense, not in the linear sense), the sale price of the home also increases.
ggplot(train,aes(x=Sale_Price/1000, fill=Exter_Qual)) +
geom_histogram(alpha=0.2, position="identity") +
labs(x = "Sales Price (Thousands $)") ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.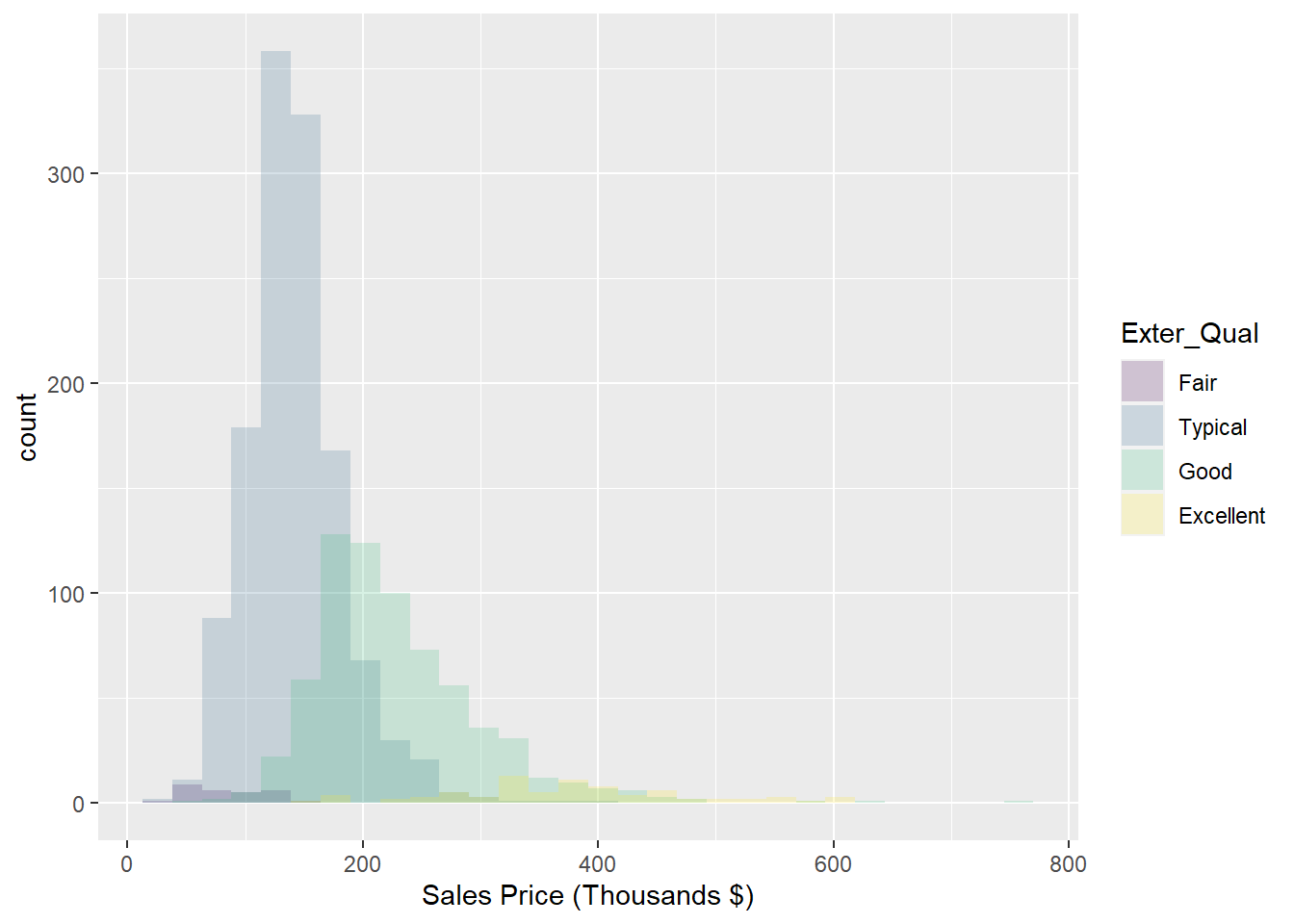
Figure 2.3: Histogram: Frequency of Sale_Price for varying qualities of home exterior
To further explore the location and spread of the data, we can create box-plots for each group using the following code:
ggplot(data = train, aes(y = Sale_Price/1000, x = `Exter_Qual`, fill = `Exter_Qual`)) +
geom_boxplot() +
labs(y = "Sales Price (Thousands $)", x = "Exterior Quality Category") +
stat_summary(fun = mean, geom = "point", shape = 20, size = 5, color = "red", fill = "red") +
scale_fill_brewer(palette="Blues") + theme_classic() + coord_flip()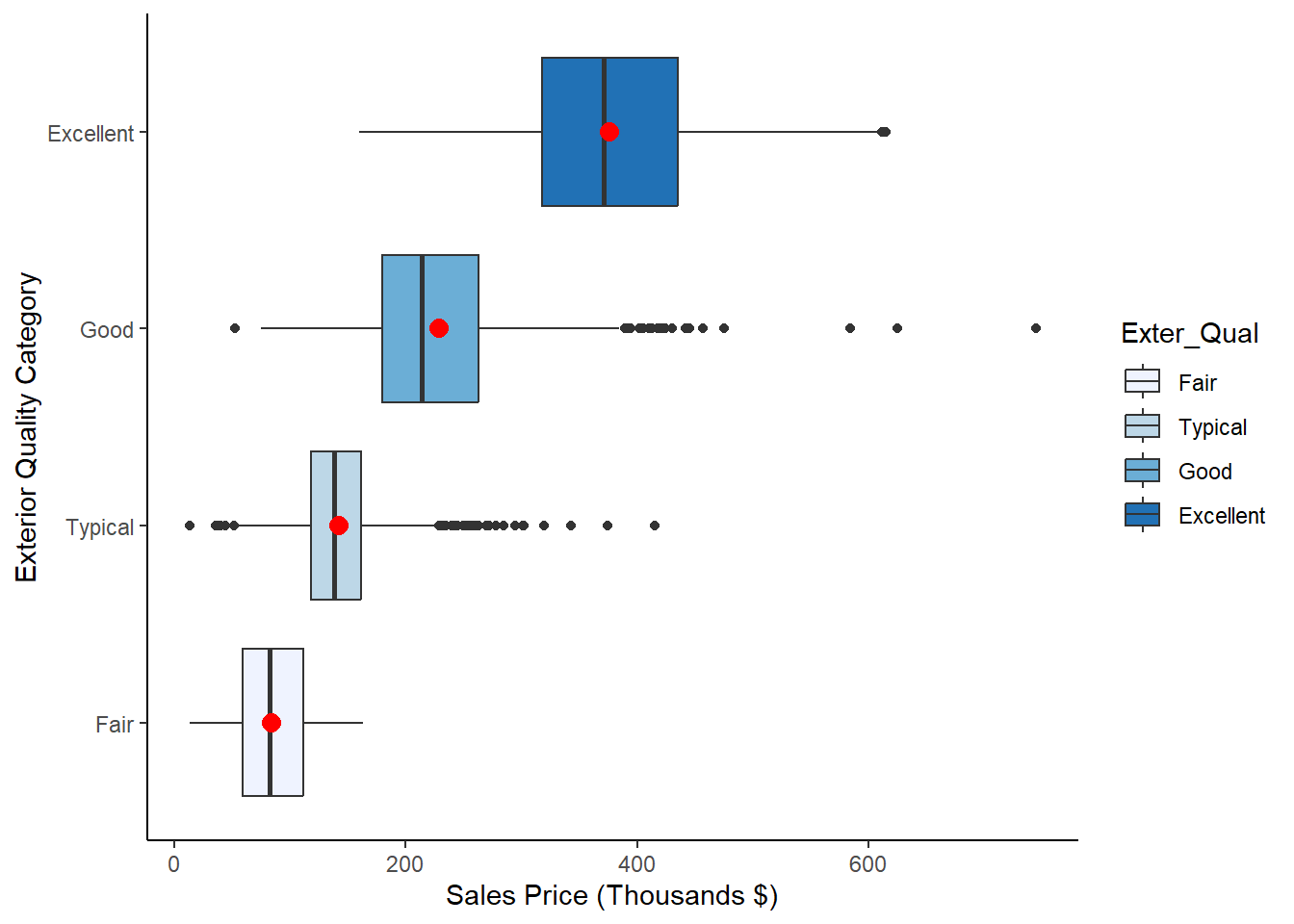
Figure 2.4: Box Plots of Sale_Price for each level of Exter_Qual
Notice that we’ve highlighted the mean on each box-plot for the purposes of comparison. We now have a hypothesis that we may want to formally test. After all, it is not good practice to look at Figures ?? and 2.4 and declare that a statistical difference exists. While we do, over time, get a feel for which visually apparent relationships turn out to be statistically significant, it’s imperative that we conduct formal testing before declaring such insights to a colleague or stakeholder.
If we want to test whether the Sale_Price is different for the different values of Exter_Qual, we have to reach for the multi-group alternative to the 2-sample t-test. This is called Analysis of Variance, or ANOVA for short.
2.3.3 Python Code
For Continuous-Continuous Associations:
p = (
ggplot(train,aes(x = "Gr_Liv_Area", y = "Sales")) +
geom_point() +
labs(y = "Sales Price (Thousands $)", x = "Greater Living Area (Sqft)")
)
p.show()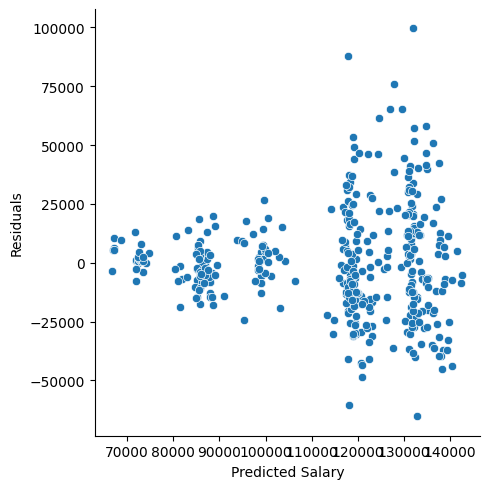
For Continuous-Categorical Associations:
p = (
ggplot(train) +
geom_bar(
aes(x="Exter_Qual", y="Sale_Price"),
stat="summary",
fun_y=np.mean,
position="dodge"
) +
scale_y_continuous(labels=lambda l: ["{:,}".format(int(x)) for x in l])
) + labs(x="External Quality",y = "Sales Price")
p.show()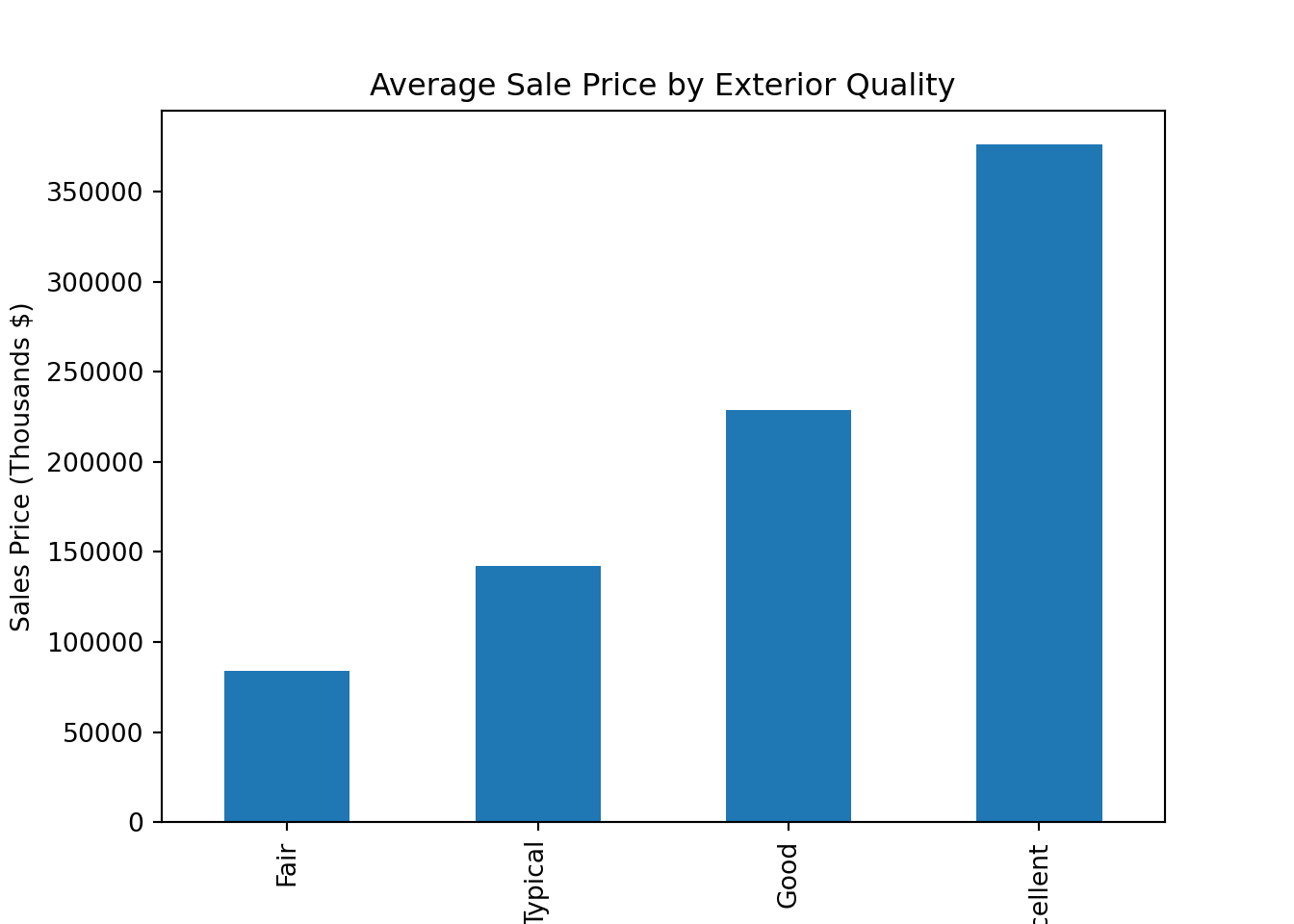
Color coded histograms:
p = (
ggplot(train,aes(x="Sales", fill="Exter_Qual")) +
geom_histogram(alpha=0.2, position="identity") +
labs(x = "Sales Price (Thousands $)")
)
p.show()## C:\PROGRA~3\ANACON~1\Lib\site-packages\plotnine\stats\stat_bin.py:109: PlotnineWarning: 'stat_bin()' using 'bins = 55'. Pick better value with 'binwidth'.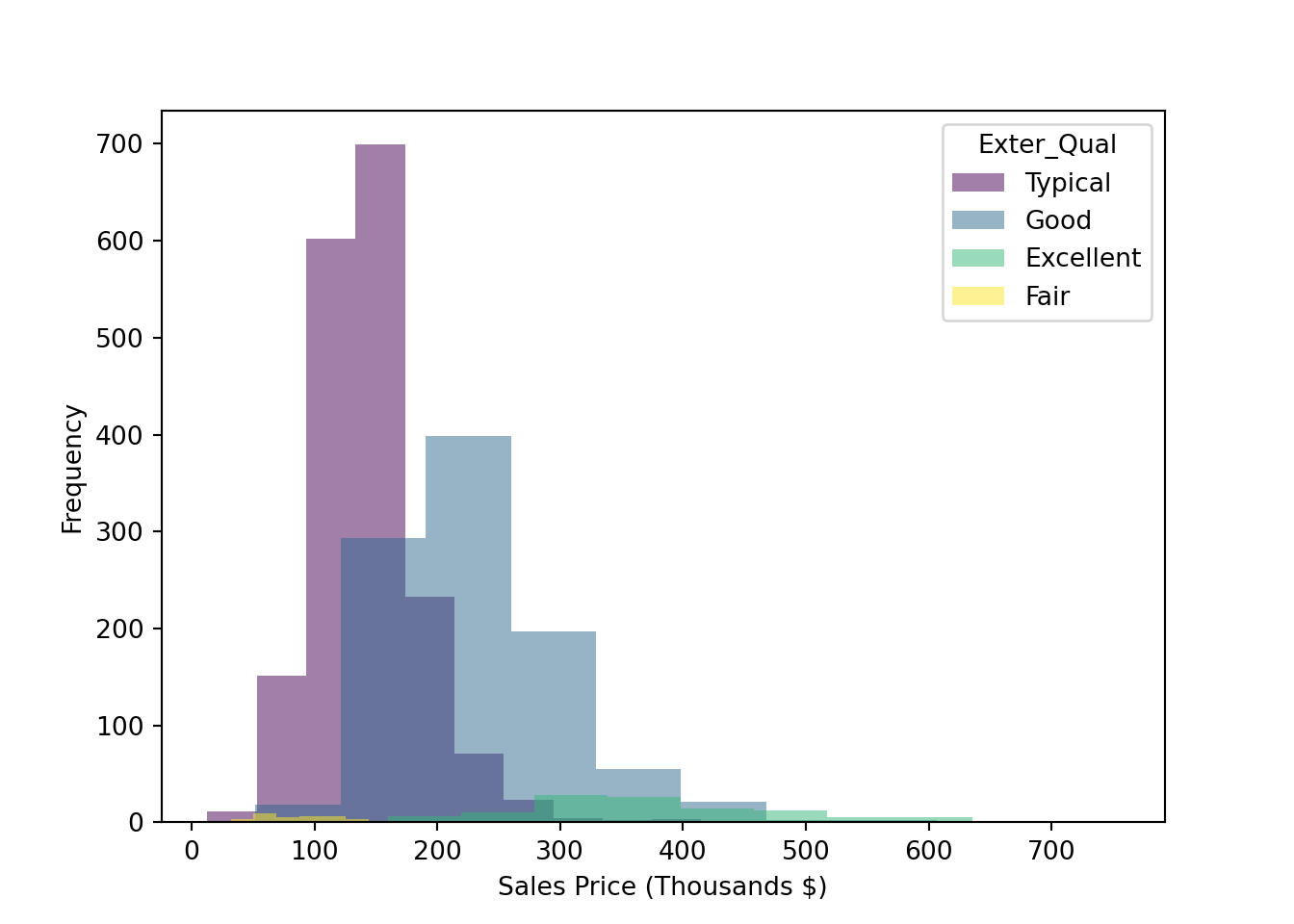
Side-by-side boxplots:
p = (
ggplot(train, aes(y = "Sales", x = "Exter_Qual", fill = "Exter_Qual")) +
geom_boxplot() +
labs(y = "Sales Price (Thousands $)", x = "Exterior Quality Category") +
stat_summary(fun_y=np.mean, geom = "point", shape="o", size = 3, color = "red", fill = "red") +
scale_fill_brewer(palette="Blues") + theme_classic() + coord_flip()
)
p.show()
2.4 One-Way ANOVA
One-way ANOVA aims to determine whether there is a difference in the mean of a continuous attribute across levels of a categorical attribute. Sound like a two-sample t-test? Indeed, it’s the extension of that test to more than two groups. Performing ANOVA with a binary input variable is mathematically identical to the two-sample t-test, assuming the variances are equal:
- The observations are independent
- The model residuals are normally distributed
- The variances for each group are equal
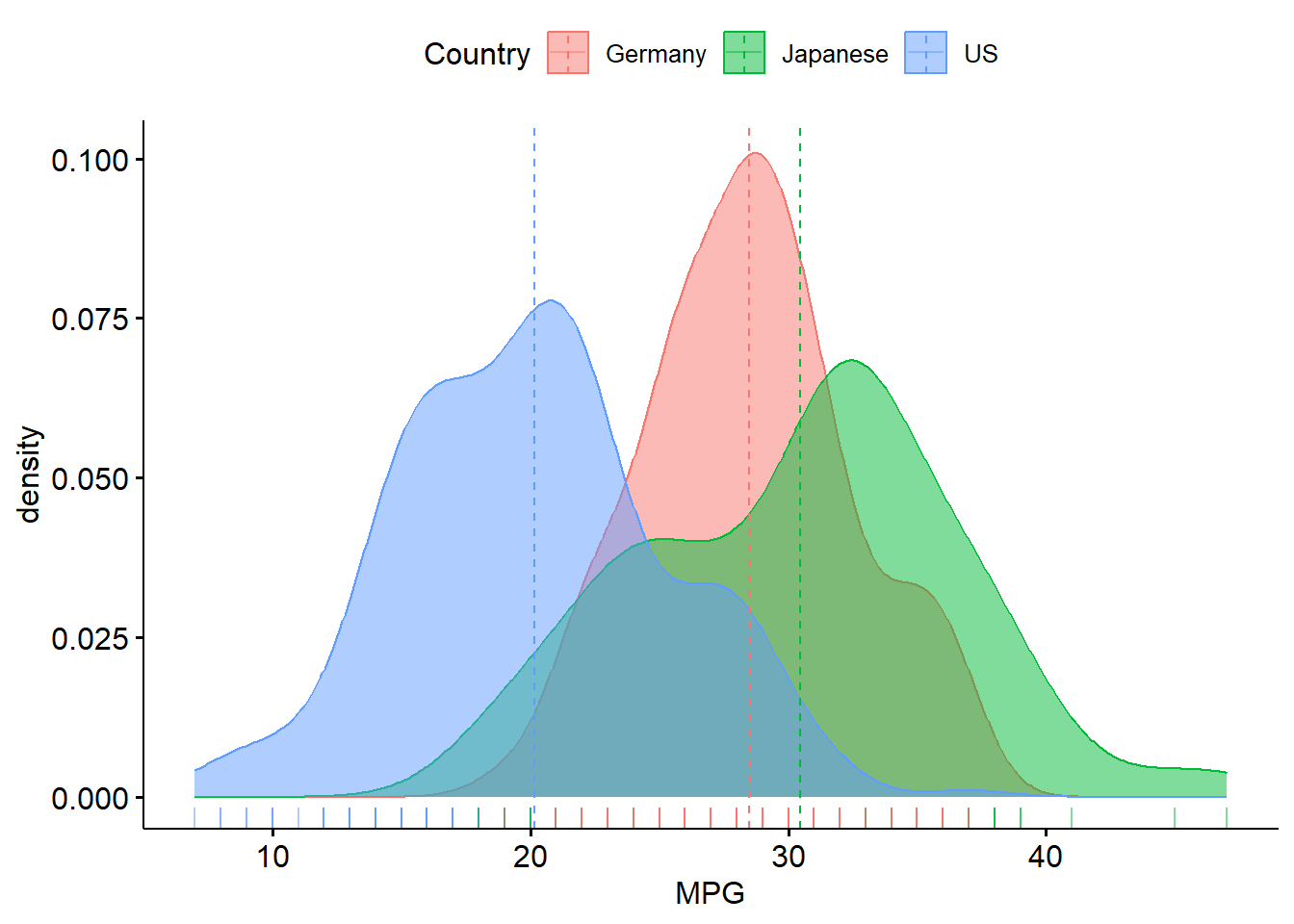
A one-way ANOVA refers to a single hypothesis test, which is \(H_{0}: \mu_{1}=\mu_{2}=...\mu_{k}\) for a predictor variable with \(k\) levels against the alternative of at least one difference. We will go back to the cars data set. There is another cars data set called “cars2” that adds cars from Germany. We can visualize this information via boxplots and density plots:
R:
library(ggpubr)
cars2<-read.csv("https://raw.githubusercontent.com/IAA-Faculty/statistical_foundations/master/cars2.csv")
ggboxplot(cars2,x="Country",y="MPG", add="mean",color="Country",fill="Country")## Warning: The `fun.y` argument of `stat_summary()` is deprecated as of ggplot2 3.3.0.
## ℹ Please use the `fun` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: The `fun.ymin` argument of `stat_summary()` is deprecated as of ggplot2 3.3.0.
## ℹ Please use the `fun.min` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: The `fun.ymax` argument of `stat_summary()` is deprecated as of ggplot2 3.3.0.
## ℹ Please use the `fun.max` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
Python:
cars2 = pd.read_csv("https://raw.githubusercontent.com/IAA-Faculty/statistical_foundations/master/cars2.csv")
p = (
ggplot(cars2, aes(x="MPG", fill="Country")) +
geom_density(alpha=0.3) + # Overlapping density curves
labs(x="MPG")
)
print(p)## <string>:2: FutureWarning: Using print(plot) to draw and show the plot figure is deprecated and will be removed in a future version. Use plot.show().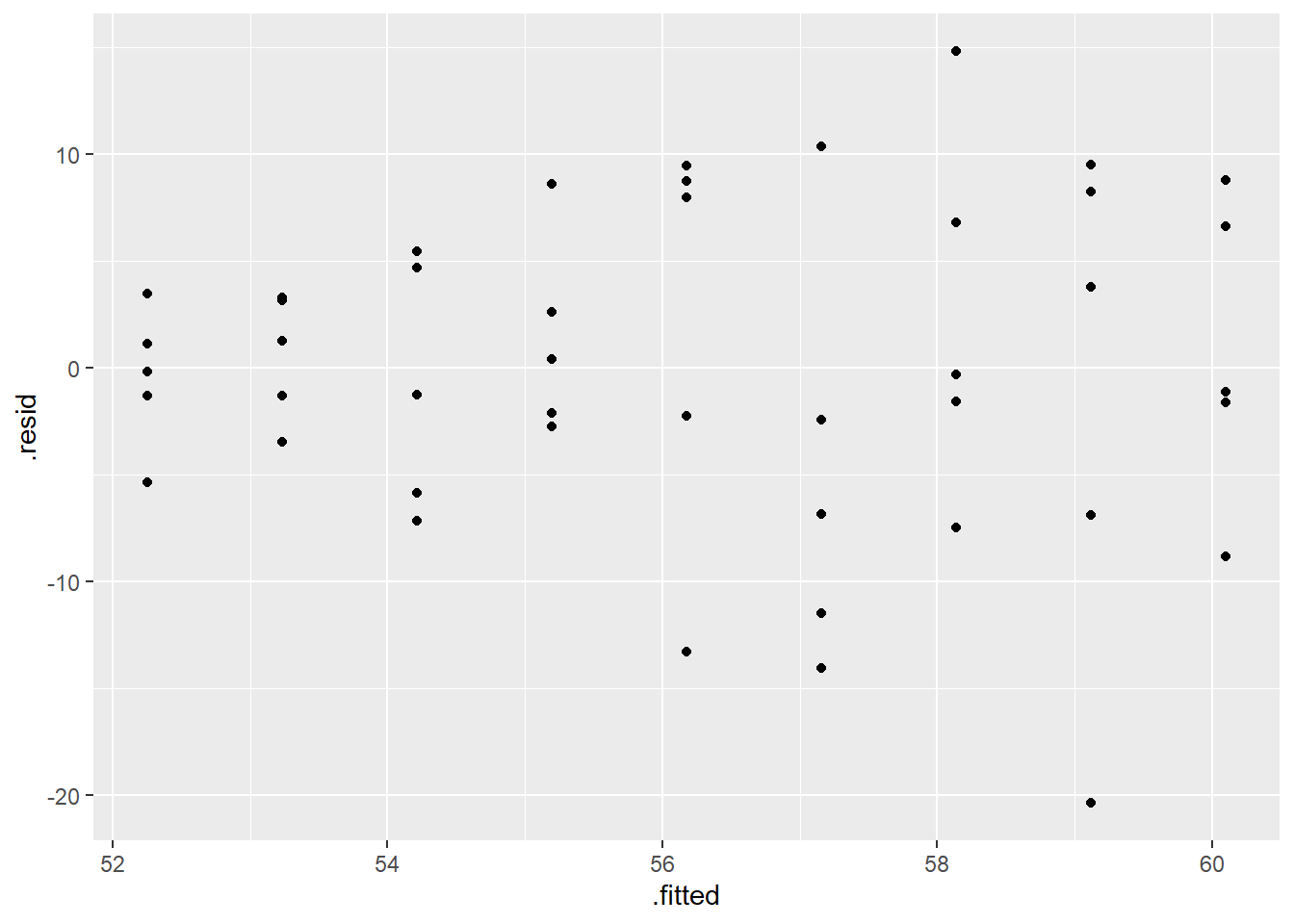
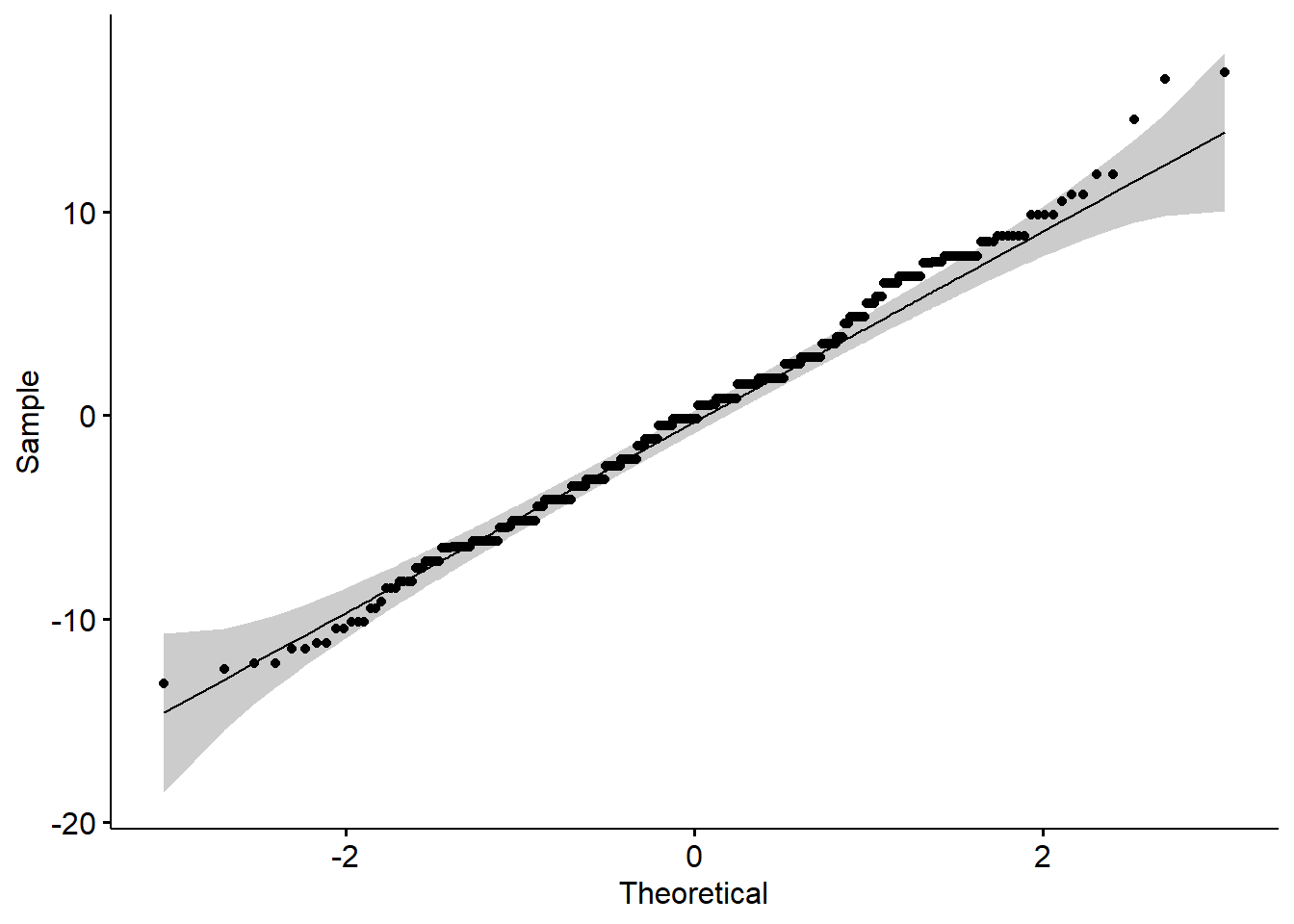
To test that the means are equal, we can use the function aov. However, we must first assess the assumptions (normality within each group and variances are equal). We can assess the normality assumption by using a QQ-plot on the residuals:
2.4.0.1 R code:
Based on residual plot, Normality appears to be a reasonable assumption.
We can also perform an hypothesis test for Normality on the residuals:
\[ H_{0}: The \; residuals \; are\; Normally\; distributed \] \[ H_{A}: The\;residuals\;are\;not \; Normally \;distributed\]
##
## Shapiro-Wilk normality test
##
## data: residuals(model)
## W = 0.99322, p-value = 0.05124Same conclusion as QQ-plot (although, they can differ!!).
Yes, we do have to run the model first to get the residuals, but we should NOT look at the output of the model until we are comforable that the assumptions hold. Since Normality is fine here, we move on to testing the variances are equal using the Levene test. The hypothesis test is:
\[ H_0: \sigma_a^2 =\sigma_b^2 =\sigma_c^2=\sigma_d^2 \quad \text{i.e., the groups have equal variance}\] \[H_a: \text{at least one group's variance is different}\]
library(car)
library(stats)
leveneTest(MPG~factor(Country),data=cars2) # Most popular, but depends on Normality## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 2 6.2318 0.00215 **
## 425
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1According to the Levene test, we reject the null hypothesis and would conclude that at least one variance is significantly different. We can also look at the residual plot.
ggplot(model, aes(.fitted, .resid)) +
geom_point() +
geom_hline(yintercept = 0)+
labs(title='Residual vs. Fitted Values Plot', x='Fitted Values', y='Residuals')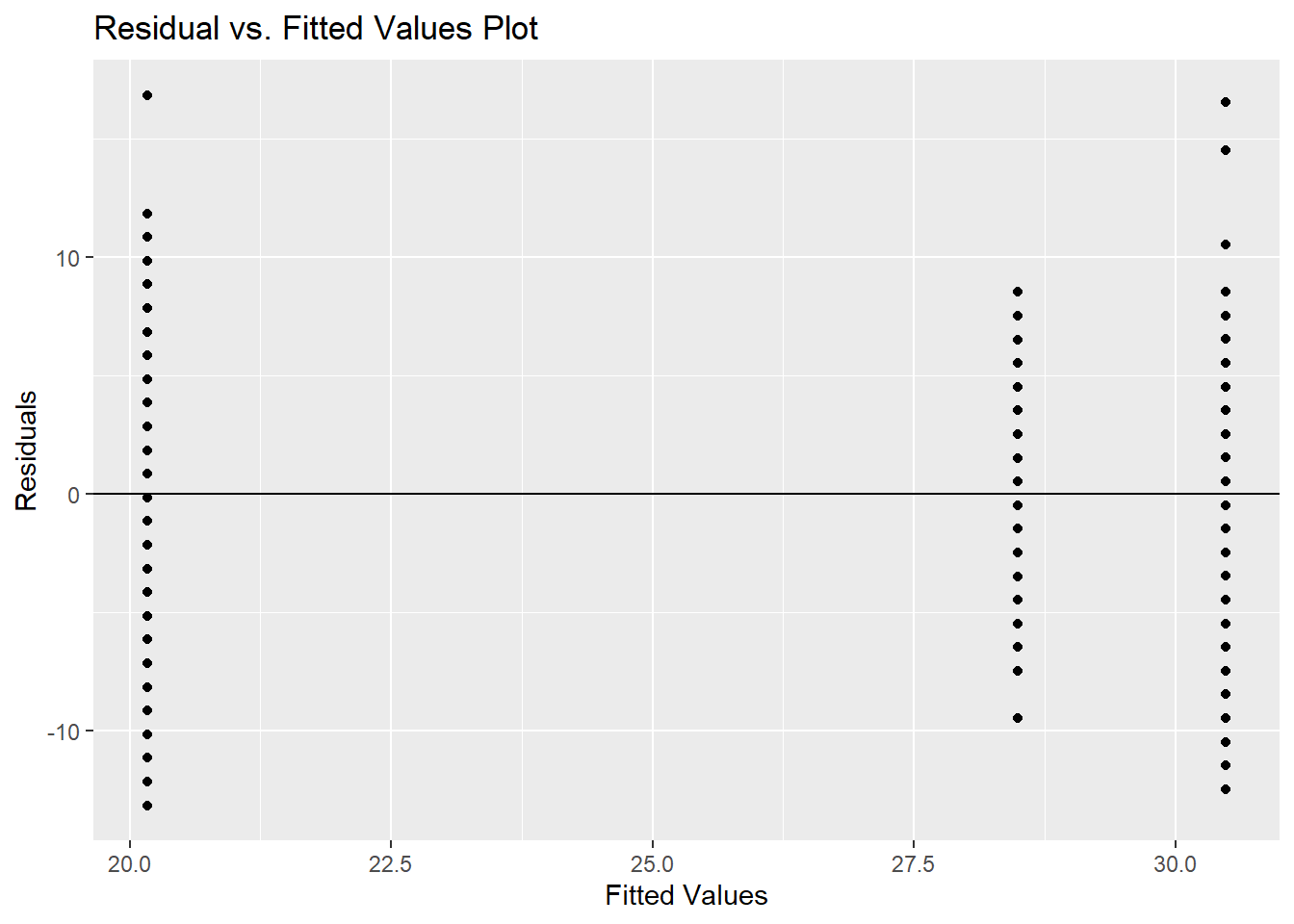
IF we were able to FAIL TO REJECT this hypothesis and felt comfortable, we could do the ANOVA:
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(Country) 2 8997 4498 172.2 <2e-16 ***
## Residuals 425 11105 26
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Our conclusion would be to reject the null hypothesis and assume that there is at least one mean that is significantly different. But remember, this test is NOT accurate since our variance are not the same.
A more appropriate test would be to perform the Welch’s One-way ANOVA. Just as with testing two means, Welch also did an extension to the ANOVA with unequal variances (this does assume Normality or at least not a too big of a departure from Normality):
##
## One-way analysis of means (not assuming equal variances)
##
## data: MPG and factor(Country)
## F = 174.97, num df = 2.0, denom df = 177.3, p-value < 2.2e-16This is still testing if there is a significant difference in the means, however, it is designed for unequal variances. We arrive at the same conclusion here…there is at least one significant difference in the mean MPG for cars made in US, Japan and Germany.
Although a one-way ANOVA is designed to assess whether or not there is a significant difference within the mean values of the response with respect to the different levels of the predictor variable, we can draw some parallel to the regression model. For example, if we have \(k\)=4, then we can let \(x_a\), \(x_b\), and \(x_c\) be 3 reference-coded dummy variables for the levels: a, b, c, and d. Note that we only have 3 dummy variables because one gets left out for the reference level, in this case it is d. The linear model is of the following form:
\[\begin{equation} y=\beta_0 + \beta_ax_a+\beta_bx_b+\beta_cx_c + \varepsilon \tag{2.2} \end{equation}\]
If we define \(x_a\) as 1 if the observation belongs to level a and 0 otherwise, and the same definition for \(x_b\) and \(x_c\), then this is called reference-level coding (this will change for effects-level coding). The predicted values in (2.2) is basically the predicted mean of the response within the 4 levels of the predictor variable.
- \(\beta_0\) represents the mean of reference group, group
d. - \(\beta_a, \beta_b, \beta_c\) all represent the difference in the respective group means compared to the reference level. Positive values thus reflect a group mean that is higher than the reference group, and negative values reflect a group mean lower than the reference group.
- \(\varepsilon\) is called the error.
A one-way ANOVA model only contains a single input variable of interest. Equation (2.2), while it has 3 dummy variable inputs, only contains a single nominal attribute. In 3, we will add more inputs to the equation via two-way ANOVA and multivariate regression models.
ANOVA is used to test the following hypothesis:
\[H_0: \beta_a=\beta_b=\beta_c = 0 \quad\text{(i.e. all group means are equal)}\]
\[H_0: \beta_a\neq0\mbox{ or }\beta_b\neq0 \mbox{ or } \beta_c \neq 0 \quad\text{(i.e. at least one is different)}\]
Both the lm() function and the aov() function will provide the p-values to test the hypothesis above, the only difference between the two functions is that lm() will also provide the user with the coefficient of determinination, \(R^2\), which tells you how much of the variation in \(y\) is accounted for by your categorical input.
##
## Call:
## lm(formula = MPG ~ factor(Country), data = cars2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.1647 -3.4900 -0.1647 2.8353 16.8353
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 28.4900 0.5112 55.735 <2e-16 ***
## factor(Country)Japanese 1.9910 0.7694 2.588 0.01 **
## factor(Country)US -8.3253 0.6052 -13.757 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.112 on 425 degrees of freedom
## Multiple R-squared: 0.4476, Adjusted R-squared: 0.445
## F-statistic: 172.2 on 2 and 425 DF, p-value: < 2.2e-16We can also confirm what we know about the predictions from ANOVA, that there are only \(k\) unique predictions from an ANOVA with \(k\) groups (the predictions being the group means), using the predict function.
cars2$predict <- predict(cars_lm, data = cars2)
cars2$resid_anova <- resid(cars_lm, data = cars2)
model_output<-cars2 %>% dplyr::select(Country, predict, resid_anova)
rbind(model_output[1:3,],model_output[255:257,],model_output[375:377,])## Country predict resid_anova
## 1 US 20.16466 -13.164659
## 2 US 20.16466 -12.164659
## 3 US 20.16466 -12.164659
## 255 Japanese 30.48101 4.518987
## 256 Japanese 30.48101 -6.481013
## 257 Japanese 30.48101 -11.481013
## 375 Germany 28.49000 -9.490000
## 376 Germany 28.49000 -2.490000
## 377 Germany 28.49000 8.510000A non-parametric version of the ANOVA test, the Kruskal-Wallis test, is also available. This test does NOT assume normality, but does need similar distributions among the different levels. Non-parametric tests do not have the same statistical power to detect differences between groups. Statistical power is the probability of detecting an effect, if there is a true effect present to detect. We should opt for these tests in situations where our data is ordinal or otherwise violates the assumptions of normality in ways that cannot be fixed by logarithmic or other similar transformation.
2.4.1 Python Code
Using a linear regression approach:
import statsmodels.formula.api as smf
model = smf.ols("MPG ~ C(Country)", data = cars2).fit()
#### Assuming constant variance and Normality:
model.summary()| Dep. Variable: | MPG | R-squared: | 0.448 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.445 |
| Method: | Least Squares | F-statistic: | 172.2 |
| Date: | Tue, 24 Jun 2025 | Prob (F-statistic): | 1.72e-55 |
| Time: | 08:23:49 | Log-Likelihood: | -1304.1 |
| No. Observations: | 428 | AIC: | 2614. |
| Df Residuals: | 425 | BIC: | 2626. |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 28.4900 | 0.511 | 55.735 | 0.000 | 27.485 | 29.495 |
| C(Country)[T.Japanese] | 1.9910 | 0.769 | 2.588 | 0.010 | 0.479 | 3.503 |
| C(Country)[T.US] | -8.3253 | 0.605 | -13.757 | 0.000 | -9.515 | -7.136 |
| Omnibus: | 1.367 | Durbin-Watson: | 0.598 |
|---|---|---|---|
| Prob(Omnibus): | 0.505 | Jarque-Bera (JB): | 1.281 |
| Skew: | 0.134 | Prob(JB): | 0.527 |
| Kurtosis: | 3.017 | Cond. No. | 4.72 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
f_stat = model.fvalue
pvalue = model.f_pvalue
# Print the result
print(f"Overall F-statistic: {f_stat:.4f}")## Overall F-statistic: 172.1621## P-value: 0.0000To get the actual F statistic:
#### Assuming constant variance and Normality:
anova_table = sm.api.stats.anova_lm(model, typ=2)
# Extract F-statistic and p-value for the factor of interest
f_stat = anova_table.loc['C(Country)', 'F']
p_val = anova_table.loc['C(Country)', 'PR(>F)']
print(f"F-statistic: {f_stat:.4f}")## F-statistic: 172.1621## P-value: 1.716e-55However, you need to test Normality and constant variance first!! To test Normality:
cars2["resid"]=model.resid
p = (
ggplot(cars2, aes(sample="resid")) +
geom_qq() +
geom_qq_line(color="blue", linetype="dashed") +
labs(title="QQ Plot of Residuals", x="Theoretical Quantiles", y="Sample Quantiles")
)
p.show()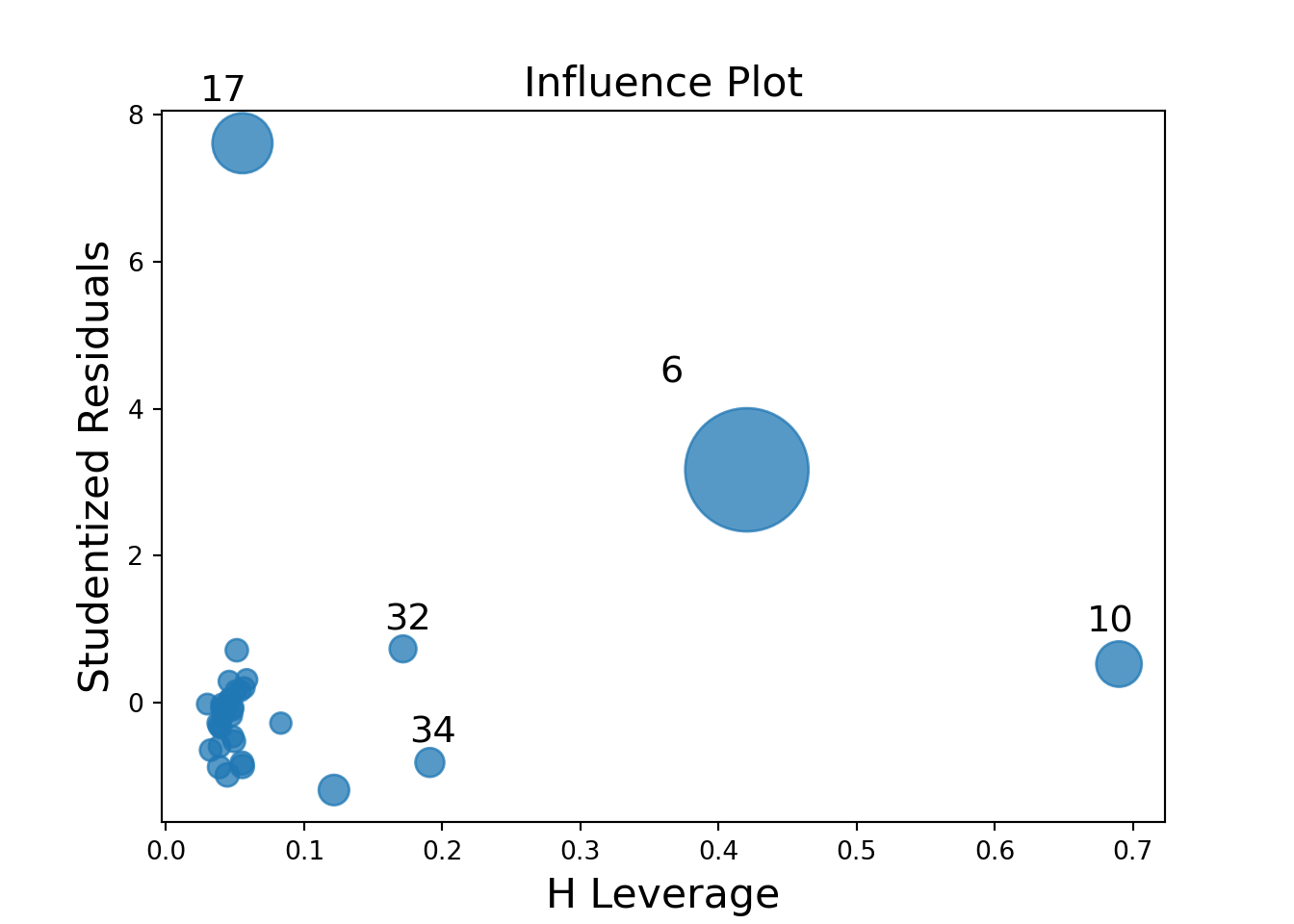
We can perform the Shapiro-Wilks test:
## P-value is: 0.051239Testing homogeneity of variance:
US = cars2[cars2['Country']=='US']['MPG']
Japan = cars2[cars2['Country']=='Japanese']['MPG']
Germany = cars2[cars2['Country']=='Germany']['MPG']
sp.stats.levene(US, Japan, Germany)## LeveneResult(statistic=6.2318084472367925, pvalue=0.002150233030133631)With visual inspection:
cars2['resid']=model.resid
cars2['predicted']=model.fittedvalues
p=(ggplot(cars2, aes(x='predicted',y='resid')) + geom_point() +
geom_hline(yintercept = 0) +
labs(x="Fitted Values", y="Residuals")
)
p.show()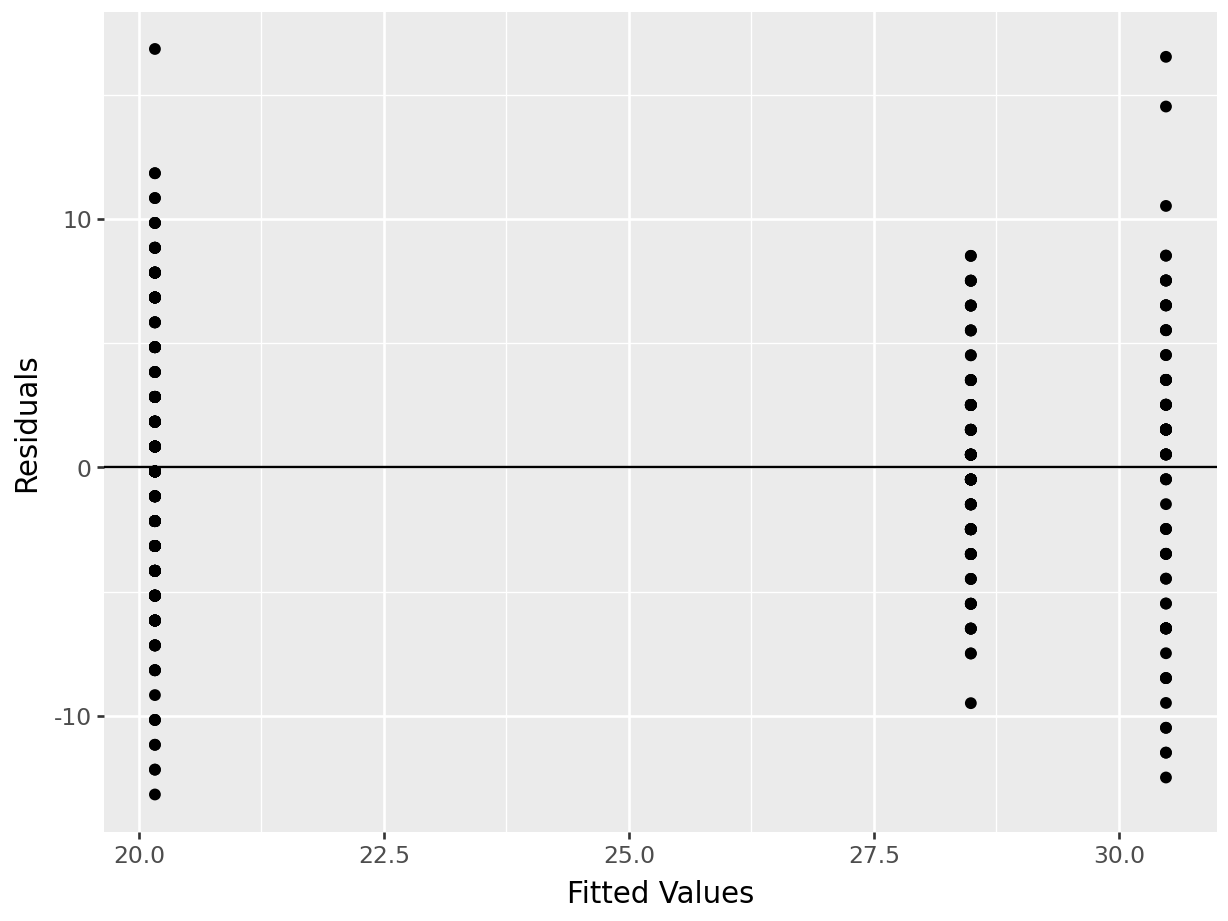
Test of homogeneity of variance if we are not comfortable with Normality:
## FlignerResult(statistic=12.256860385255132, pvalue=0.0021800004568268377)There are other functions that can perform a one-way ANOVA. For example,
Using statsmodels for Welch’s ANOVA:
model = sm.stats.oneway.anova_oneway(data = cars2['MPG'], groups = cars2['Country'], welch_correction = True)
print(f"The F-statistic is: {model.statistic:.4f}")## The F-statistic is: 174.9733## The p-value is: 0.0000Scipy is able to do the basic ANOVA:
## F_onewayResult(statistic=172.16207245035605, pvalue=1.7155684156623464e-55)2.4.2 Kruskal-Wallis
The Kruskal-Wallis test, proposed in 1952, is equivalent to a parametric one-way ANOVA where the data values have been replaced with their ranks (i.e. largest value = 1, second largest value = 2, etc.). When the data is not normally distributed but is identically distributed (having the same shape and variance), the Kruskal-Wallis test can be considered a test for differences in medians. If those identical distributions are also symmetric, then Kruskal-Wallis can be interpretted as testing for a difference in means. When the data is not identically distributed, or when the distributions are not symmetric, Kruskal-Wallis is a test of dominance between distributions. Distributional dominance is the notion that one group’s distribution is located at larger values than another, probabilistically speaking. Formally, a random variable A has dominance over random variable B if \(P(A\geq x) \geq P(B\geq x)\) for all \(x\), and for some \(x\), \(P(A\geq x) > P(B\geq x)\).
We summarize this information in the following table:
| Conditions |
Interpretation of Significant Kruskal-Wallis Test |
|
Group distributions are identical in shape, variance, and symmetric | Difference in means |
|
Group distributions are identical in shape, but not symmetric | Difference in medians |
|
Group distributions are not identical in shape, variance, and are not symmetric |
Difference in location. (distributional dominance) |
Implementing the Kruskal-Wallis test in R is simple:
2.4.2.1 R code:
##
## Fligner-Killeen test of homogeneity of variances
##
## data: MPG by Country
## Fligner-Killeen:med chi-squared = 12.257, df = 2, p-value = 0.00218##
## Kruskal-Wallis rank sum test
##
## data: MPG by factor(Country)
## Kruskal-Wallis chi-squared = 197.74, df = 2, p-value < 2.2e-16Our conclusion would be that the distribution of sale price is different across different levels of exterior quality.
2.5 ANOVA Post-hoc Testing
After performing an ANOVA and learning that there is a difference between the groups of data, our next natural question ought to be which groups of data are different, and how? In order to explore this question, we must first consider the notion of experimentwise error. When conducting multiple hypothesis tests simultaneously, the experimentwise error rate is the proportion of time you expect to make an error in at least one test.
Let’s suppose we are comparing grocery spending on 4 different credit card rewards programs. If we’d like to compare the rewards programs pairwise, that entails 6 different hypothesis tests (each is a two-sample t-test). If we keep a confidence level of \(\alpha = 0.05\) and subsequently view “being wrong in one test” as a random event happening with probability \(p=0.05\) then our probability of being wrong in at least one test out of 6 could be as great as 0.26!
To control this experiment-wise error rate, we must lower our significance thresholds to account for it. Alternatively, we can view this as an adjustment of our p-values higher while keeping our significance threshold fixed as usual. This is typically the approach taken, as we prefer to fix our significance thresholds in accordance with previous literature or industry standards. There are many methods of adjustment that have been proposed over the years for this purpose. Here, we consider a few popular methods: Tukey’s test (when a basic ANOVA is done), Games-Howell test (when Welch’s ANOVA is done), Dunn’s test (when Kruskal-Wallis test is done) for pairwise comparisons and Dunnett’s test (or Bootstrap with correction) for control group comparisons.
2.5.1 Tukey-Kramer
If our objective is to compare each group to every other group then Tukey’s test of honest significant differences, also known as the Tukey-Kramer test is probably the most widely-available and popular corrections in practice (should ONLY be used if you do the basic ANOVA). However, it should be noted that Tukey’s test should not be used if one does not plan to make all pairwise comparisons. If only a subset of comparisons are of interest to the user (like comparisons only to a control group) then one should opt for the Dunnett or a modified Bonferroni correction.
2.5.1.1 R code:
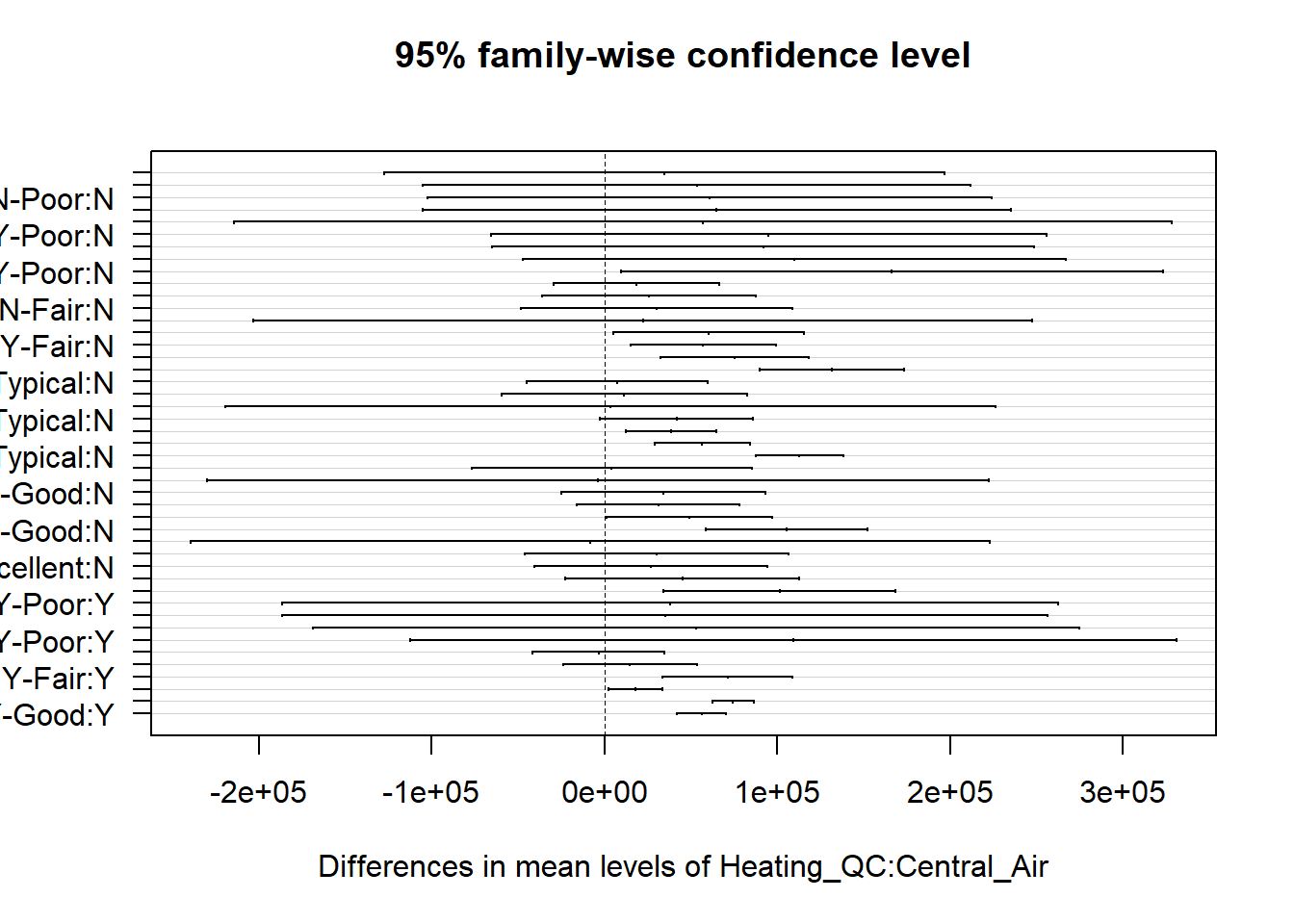
To employ Tukey’s HSD in R, we must use the aov() function to create our ANOVA object rather than the lm() function. The output of the test shows the difference in means and the p-value for testing the null hypothesis that the means are equal (i.e. that the differences are equal to 0).
cars_aov <- aov(MPG~factor(Country), data = cars2)
tukey.cars <- TukeyHSD(cars_aov)
print(tukey.cars)## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = MPG ~ factor(Country), data = cars2)
##
## $`factor(Country)`
## diff lwr upr p adj
## Japanese-Germany 1.991013 0.1813164 3.800709 0.0269593
## US-Germany -8.325341 -9.7486718 -6.902011 0.0000000
## US-Japanese -10.316354 -11.8687997 -8.763908 0.0000000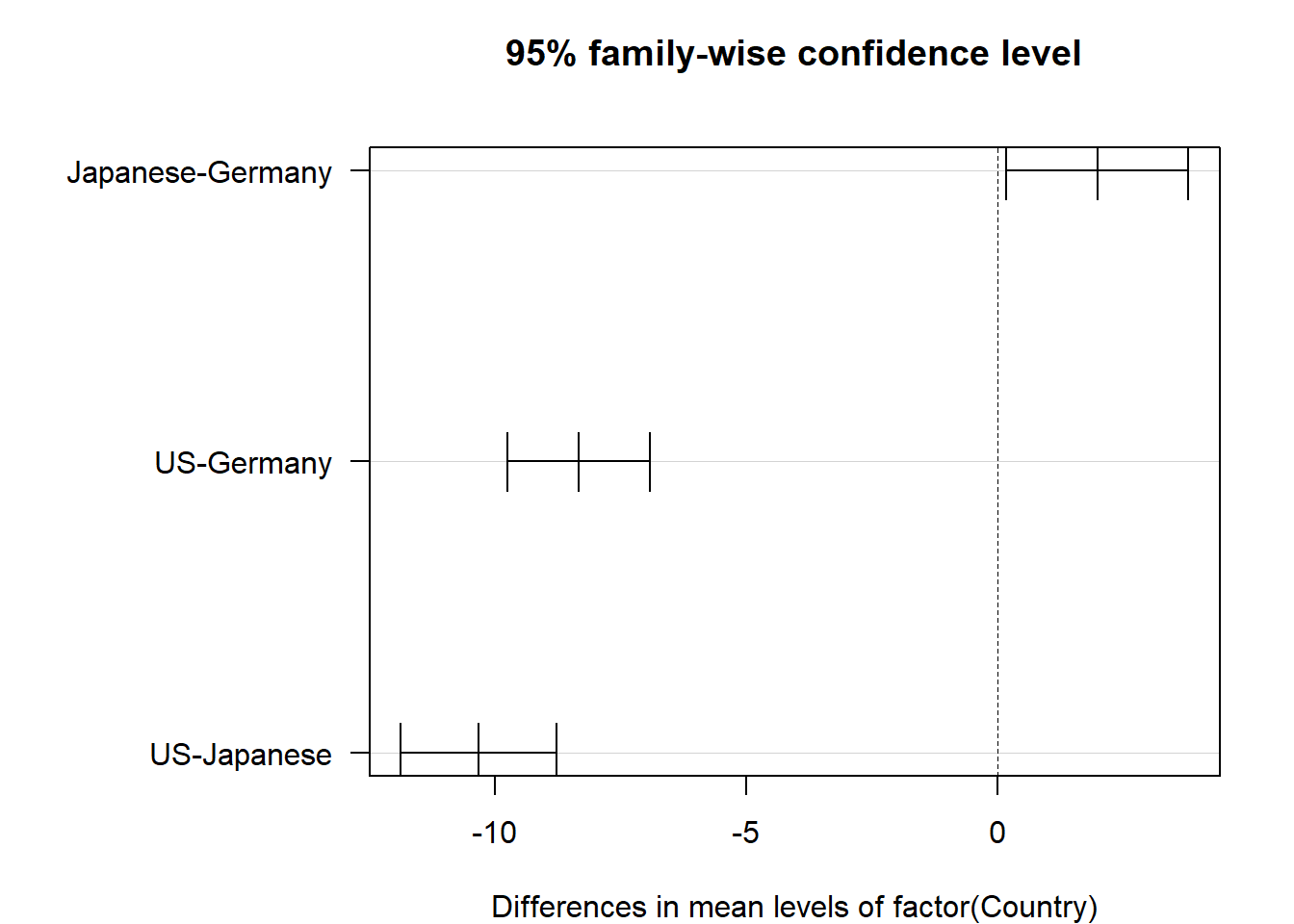
Figure 2.5: Confidence intervals for mean differences adjusted via Tukey-Kramer
The p-values in this table have been adjusted higher to account for the possible experimentwise error rate. For every pairwise comparison shown, we reject the null hypothesis and conclude that the mean MPG is different among the US, Japanese and German made cars. Furthermore, Figure 2.5 shows us experiment-wise (family-wise) adjusted confidence intervals for the differences in means for each pair. The plot option las=1 guides the axis labels. Type ?par for a list of plot options for base R, including an explanation of las.
If we utilized the Welch’s ANOVA (assumed variances were NOT equal), then we would use the Games-Howell test:
library(PMCMRplus)
cars_aov <- aov(MPG~factor(Country), data=cars2)
gh.cars <- gamesHowellTest(cars_aov)
summary(gh.cars)##
## Pairwise comparisons using Games-Howell test## data: MPG by factor(Country)## alternative hypothesis: two.sided## P value adjustment method: none## H0## q value Pr(>|q|)
## Japanese - Germany == 0 3.547 0.035479 *
## US - Germany == 0 -22.859 5.3291e-15 ***
## US - Japanese == 0 -19.164 4.3188e-14 ***## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The conclusion from the Games-Howell test is similar to Tukey’s test.
However, if we use Kruskal-Wallis test, then we would use the Dunn’s test for multiple comparisons:
## Kruskal-Wallis rank sum test
##
## data: x and group
## Kruskal-Wallis chi-squared = 197.7403, df = 2, p-value = 0
##
##
## Comparison of x by group
## (Bonferroni)
## Col Mean-|
## Row Mean | Germany Japanese
## ---------+----------------------
## Japanese | -1.147428
## | 0.3768
## |
## US | 10.95670 11.38301
## | 0.0000* 0.0000*
##
## alpha = 0.05
## Reject Ho if p <= alpha/2This is a nonparametric test and does not have as much power as the previous multiple comparisons. Be sure you use the correct test based on what you see in the data.
You can also use the bootstrap technique (similar to what you did when testing two populution means)….you will need to adjust the alpha level.
2.5.2 Dunnett’s Test
If the plan is to make fewer comparisons, specifically just \(k-1\) comparisons where \(k\) is the number of groups in your data (indicating you plan to compare all the groups to one specific group, usually the control group), then Dunnett’s test would be preferrable to the Tukey-Kramer test. If all pairwise comparisons are not made, the Tukey-Kramer test is overly conservative, creating a confidence level that is much lower than specified by the user. Dunnett’s test factors in fewer comparisons and thus should not be used for tests of all pairwise comparisons.
To use Dunnett’s test (should only be used with basic ANOVA), we must add the DescTools package to our library. The control group to which all other groups will be compared is designated by the control= option.
cars2$group<-ifelse(cars2$Country=="US","aUS",cars2$Country)
dunnettTest(x = cars2$MPG, g = factor(cars2$group))## aUS
## Germany < 2e-16
## Japanese 4.4e-16In the output from Dunnett’s test, we see that Japanese and German made cars are significantly different than US made cars (note that this does not compare Japanese to German!).
If we are not able to assume equal variances, we can use the Bootstrap two-sample test to compare each group to the control and then adjust the p-value using Bonferroni.
US=cars2$MPG[cars2$Country=="US"]
Japan = cars2$MPG[cars2$Country=="Japanese"]
Germany = cars2$MPG[cars2$Country=="Germany"]
US_Japan = boot(US, Japan, 'ne', 0.05)
x2 = Germany
US_Germany = boot(US, Germany, 'ne', 0.05)
pval= c(2*US_Japan[[2]],2*US_Germany[[2]])
pval## [1] 0 02.5.3 Python Code
Tukey-Kramer test:
import statsmodels.stats.multicomp as mc
comp = mc.MultiComparison(cars2['MPG'], cars2['Country'])
ph_res = comp.tukeyhsd(alpha = 0.05)
ph_res.summary()| group1 | group2 | meandiff | p-adj | lower | upper | reject |
|---|---|---|---|---|---|---|
| Germany | Japanese | 1.991 | 0.027 | 0.1813 | 3.8007 | True |
| Germany | US | -8.3253 | 0.0 | -9.7487 | -6.902 | True |
| Japanese | US | -10.3164 | 0.0 | -11.8688 | -8.7639 | True |

Games-Howell test (DO NOT RECOMMEND):
# Games-Howell post hoc test
import pingouin as pg
results = pg.pairwise_gameshowell(dv='MPG', between='Country', data=cars2)
print(results)## A B mean(A) ... df pval hedges
## 0 Germany Japanese 28.490000 ... 127.635392 3.547851e-02 -0.394392
## 1 Germany US 28.490000 ... 235.926277 0.000000e+00 1.709407
## 2 Japanese US 30.481013 ... 115.635369 6.072920e-14 1.902457
##
## [3 rows x 10 columns]Dunn’s test:
import scikit_posthocs as scp
result = scp.posthoc_dunn(cars2, val_col='MPG', group_col='Country', p_adjust='Bonferroni')
print(result)## Germany Japanese US
## Germany 1.000000e+00 7.536132e-01 1.851171e-27
## Japanese 7.536132e-01 1.000000e+00 1.524401e-29
## US 1.851171e-27 1.524401e-29 1.000000e+00No Dunnett’s test in Python. The team at statsmodels is supposedly “working on it”.
Bootstrap correction:
US = cars2['MPG'][cars2['Country']=='US']
Japan = cars2['MPG'][cars2['Country']=='Japanese']
Germany = cars2['MPG'][cars2['Country']=='Germany']
result_J,pval_J = boot(US, Japan, 'ne', 0.05)
result_G,pval_G = boot(US, Germany, 'ne', 0.05)
2*pval_J## 0.0## 0.0FDR correction:
from statsmodels.stats.multitest import multipletests
# Example list of raw p-values
pvals = [0.001, 0.03, 0.2, 0.4]
rejected, pvals_corrected, _, _ = multipletests(pvals, method='fdr_bh')
print("Adjusted B-H p-values:", pvals_corrected)## Adjusted B-H p-values: [0.004 0.06 0.26666667 0.4 ]rejected, pvals_corrected, _, _ = multipletests(pvals, method='bonferroni')
print("Adjusted Bonferroni p-values:", pvals_corrected)## Adjusted Bonferroni p-values: [0.004 0.12 0.8 1. ]2.6 Pearson Correlation
ANOVA is used to formally test the relationship between a categorical variable and a continuous variable. To formally test the (linear) relationship between two continuous attributes, we introduce Pearson correlation, commonly referred to as simply correlation. Correlation is a number between -1 and 1 which measures the strength of a linear relationship between two continuous attributes.
Negative values of correlation indicate a negative linear relationship, meaning that as one of the variables increases, the other tends to decrease. Similarly, positive values of correlation indicate a positive linear relationship meaning that as one of the variables increases, the other tends to increase. Absolute values of correlation equal to 1 indicate a perfect linear relationship. For example, if our data had a column for “mile time in minutes” and a column for “mile time in seconds”, these two columns would have a correlation of 1 due to the fact that there are 60 seconds in a minute. A correlation value near 0 indicates that the variables have no linear relationship.
It’s important to emphasize that Pearson correlation is only designed to detect linear associations between variables. Even when a correlation between two variables is 0, the two variables may still have a very clear association, whether it be quadratic, cyclical, or some other nonlinear pattern of association. Figure 2.6 illustrates all of these statements. On top of each scatter plot, the correlation coefficient is shown. The middle row of this figure aims to illustrate that a perfect correlation has nothing to do with the magnitude or slope of the relationship. In the center image, middle row, we note that the correlation is undefined for any pair that includes a constant variable. In that image, the value of \(y\) is constant across the sample. Equation (2.3) makes this mathematically clear.
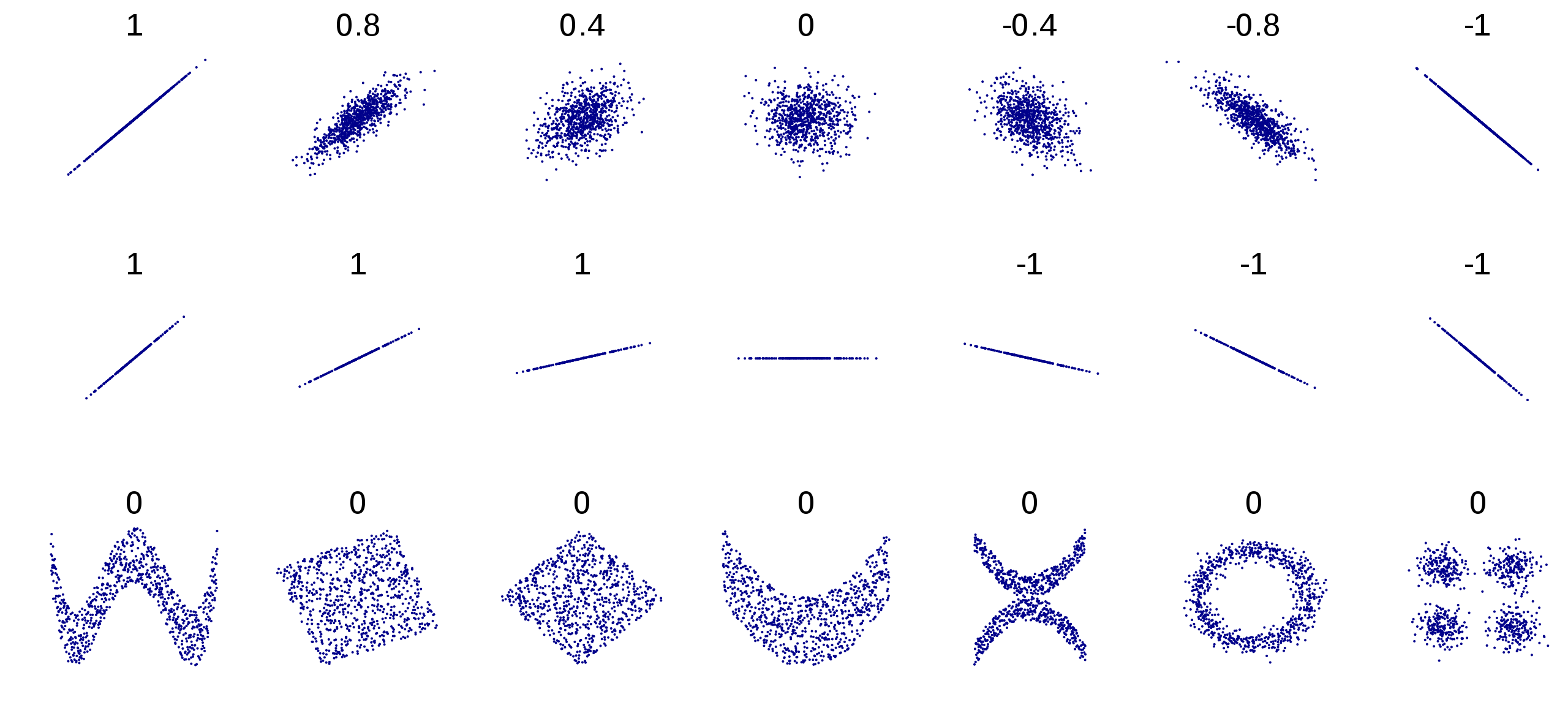
Figure 2.6: Examples of relationships and their associated correlations
The population correlation parameter is denoted \(\rho\) and estimated by the sample correlation, denoted as \(r\). The formula for the sample correlation between columns of data \(\mathbf{x}\) and \(\mathbf{y}\) is
\[\begin{equation} r = \frac{\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n (x_i-\bar{x})^2\sum_{i=1}^n(y_i-\bar{y})^2}}. \tag{2.3} \end{equation}\]
Note that with centered variable vectors \(\mathbf{x_c}\) and \(\mathbf{y_c}\) this formula becomes much cleaner with linear algebra notation:
\[\begin{equation} r = \frac{\mathbf{x_c}^T\mathbf{y_c}}{\|\mathbf{x_c}\|\|\mathbf{y_c}\|}. \tag{2.4} \end{equation}\]
It is interesting to note that Equation (2.4) is identical to the formula for the cosine of the angle between to vectors. While this geometrical relationship does not benefit our intuition1, it is noteworthy nonetheless.
Pearson’s correlation can be calculated in R with the built in cor() function, with the two continuous variables as input:
2.6.1 Statistical Test
To test the statistical significance of correlation, we use a t-test with the null hypothesis that the correlation is equal to 0:
\[H_0: \rho = 0\]
\[H_a: \rho \neq 0\]
If we can reject the null hypothesis, then we declare a significant linear association between the two variables. The cor.test() function in R will perform the test:
##
## Pearson's product-moment correlation
##
## data: x and y
## t = 43.857, df = 2049, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.6728235 0.7175145
## sample estimates:
## cor
## 0.695842We conclude that Gr_Liv_Area has a linear association with Sale_Price.
It must be noted that this t-test for Pearson’s correlation is not free from assumptions. In fact, there are 4 assumptions that must be met, and they are detailed in Section 2.7.1.
2.6.2 Effect of Anomalous Observations
One final nuance that is important to note is the effect of anomalous observations on correlation. In Figure 2.7 we display 30 random 2-dimensional data points \((x,y)\) with no linear relationship.
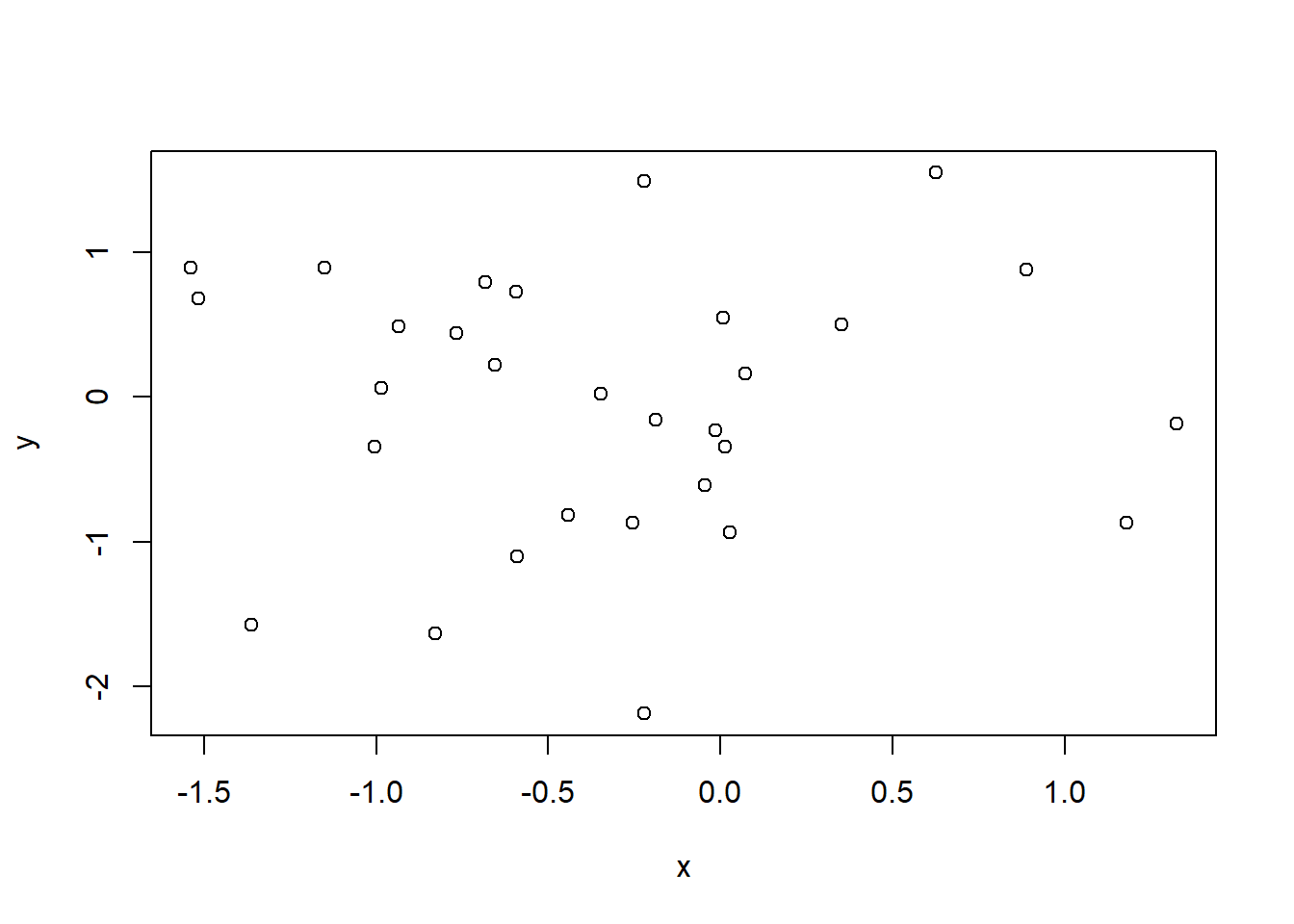
Figure 2.7: The variables x and y have no correlation
The correlation is not exactly zero (we wouldn’t expect perfection from random data) but it is very close at 0.002.
##
## Pearson's product-moment correlation
##
## data: x and y
## t = 0.012045, df = 28, p-value = 0.9905
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.3582868 0.3622484
## sample estimates:
## cor
## 0.002276214Next, we’ll add a single anomalous observation to our data and see how it affects both the correlation value and the correlation test.
##
## Pearson's product-moment correlation
##
## data: x and y
## t = 5.803, df = 29, p-value = 2.738e-06
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.5115236 0.8631548
## sample estimates:
## cor
## 0.7330043The correlation jumps to 0.73 from 0.002 and is declared strongly significant! Figure 2.8 illustrates the new data. This simple example shows why exploratory data analysis is so important! If we don’t explore our data and detect anomalous observations, we might improperly declare relationships are significant when they are driven by a single observation or a small handful of observations.
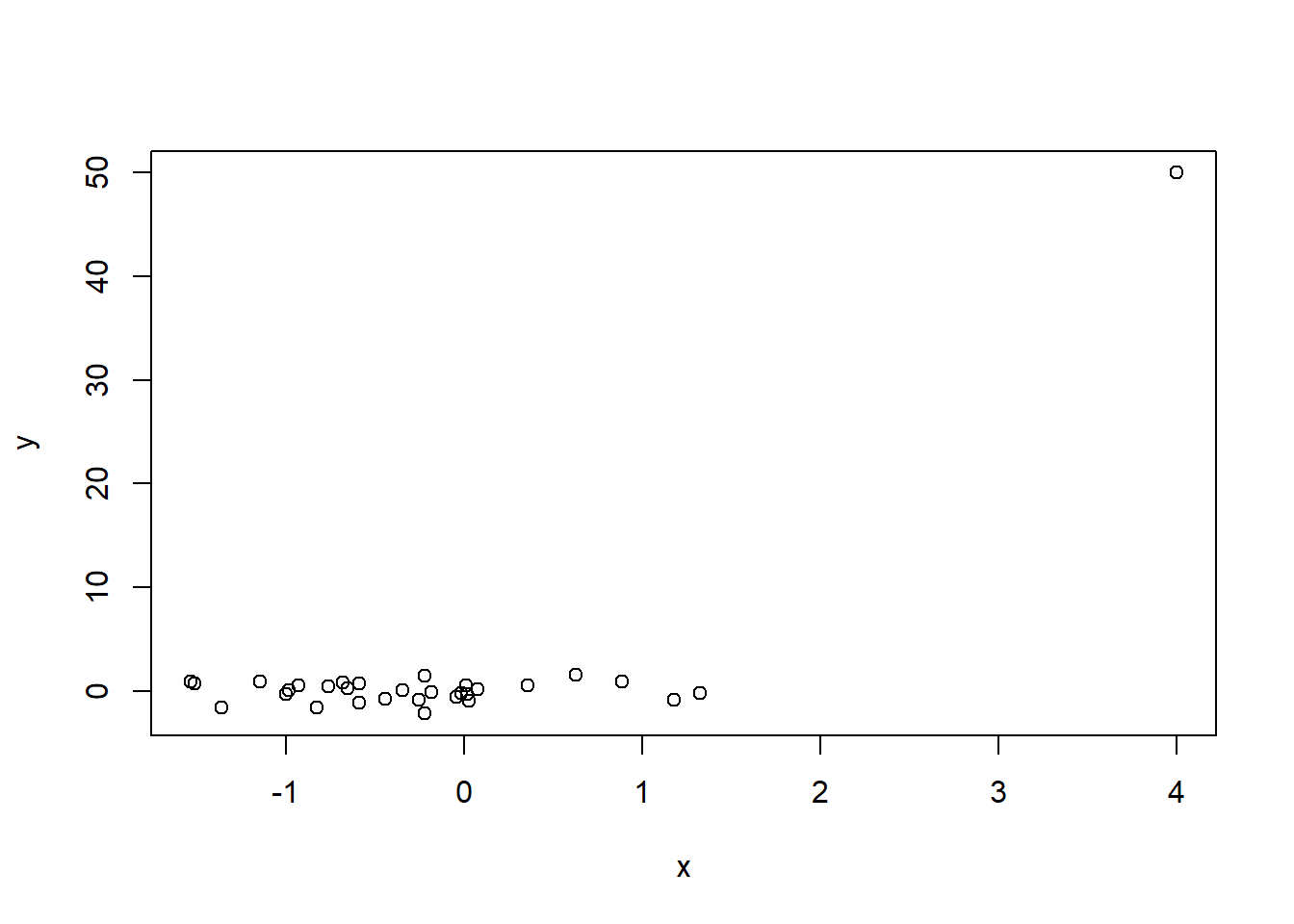
Figure 2.8: A single anomalous observation creates strong correlation (0.73) where there previously was none
2.6.3 The Correlation Matrix
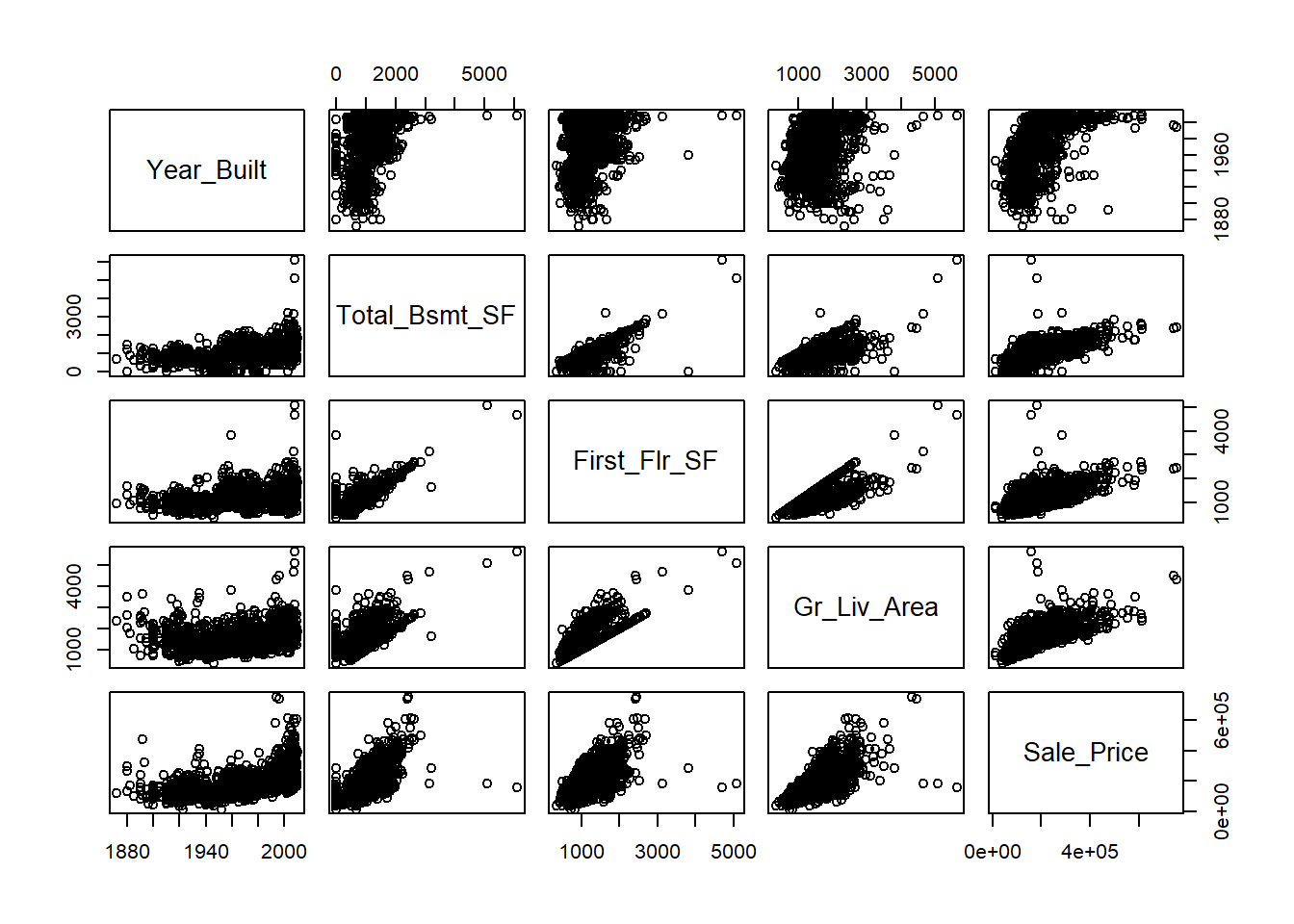
It’s common to consider and calculate all pairwise correlations between variables in a dataset. If many attributes share a high degree of mutual correlation, this can cause problems for regression as will be discussed in Chapter 5. The pairwise correlations are generally arranged in an array called the correlation matrix, where the \((i,j)^{th}\) entry is the correlation between the \(i^{th}\) variable and \(j^{th}\) variable in your list. To compute the correlation matrix, we again use the cor() function.
## Year_Built Total_Bsmt_SF First_Flr_SF Gr_Liv_Area Sale_Price
## Year_Built 1.0000000 0.4272263 0.3271756 0.2386360 0.5570318
## Total_Bsmt_SF 0.4272263 1.0000000 0.8065833 0.4538351 0.6253874
## First_Flr_SF 0.3271756 0.8065833 1.0000000 0.5713599 0.6206734
## Gr_Liv_Area 0.2386360 0.4538351 0.5713599 1.0000000 0.6958420
## Sale_Price 0.5570318 0.6253874 0.6206734 0.6958420 1.0000000Not surprisingly, we see strong positive correlation between the square footage of the basement and that of the first floor, and also between all of the area variables and the sale price. As demonstrated by Figures 2.6 and 2.8, raw correlation values can be misleading and it’s unwise to calculate them without a scatter plot for context. The pairs() function in base R provides a simple matrix of scatterplots for this purpose.
2.6.4 Python Code
Pearson’s correlation
## array([[1. , 0.69584201],
## [0.69584201, 1. ]])Statistical test for Correlation
## PearsonRResult(statistic=0.6958420133893222, pvalue=6.980207969293157e-297)Correlation Matrix
train_plot= train[['Year_Built', 'Total_Bsmt_SF', 'First_Flr_SF', 'Gr_Liv_Area', 'Sale_Price']]
np.corrcoef(train_plot, rowvar = False)## array([[1. , 0.42722628, 0.32717559, 0.23863599, 0.55703178],
## [0.42722628, 1. , 0.80658329, 0.45383515, 0.62538744],
## [0.32717559, 0.80658329, 1. , 0.57135986, 0.62067339],
## [0.23863599, 0.45383515, 0.57135986, 1. , 0.69584201],
## [0.55703178, 0.62538744, 0.62067339, 0.69584201, 1. ]])## <seaborn.axisgrid.PairGrid object at 0x0000018CF3CB8200>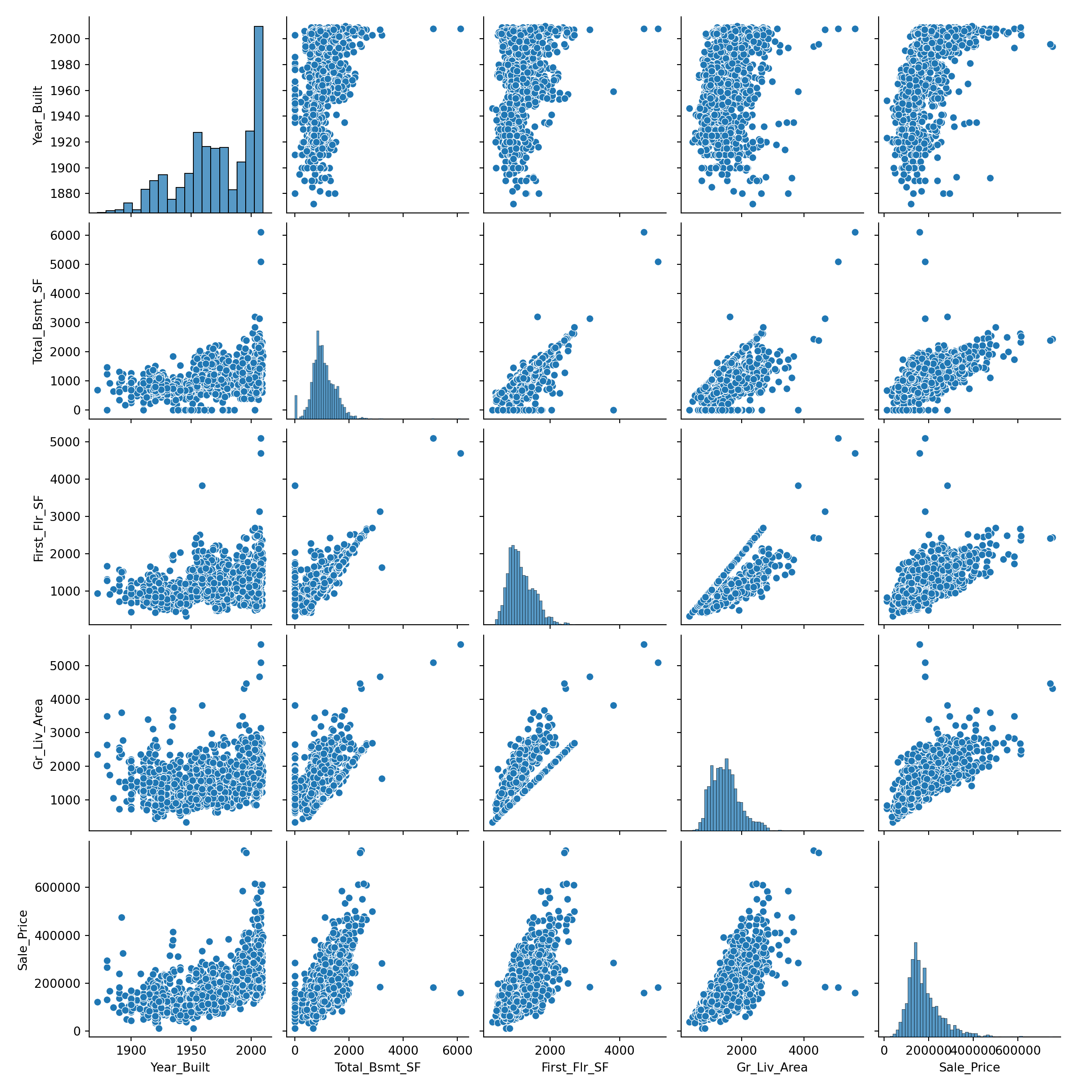
2.7 Simple Linear Regression
After learning that two variables share a linear relationship, the next question is natural: what is that relationship? How much,on average, should we expect one variable to change as the other changes by a single unit? Simple linear regression answers this question by creating a linear equation that best represents the relationship in the sense that it minimizes the squared error between the observed data and the model predictions (i.e. the sum of the squared residuals). The simple linear regression equation is typically written \[\begin{equation} y=\beta_0 + \beta_1x + \varepsilon \tag{2.5} \end{equation}\] where \(\beta_0\), the intercept, gives the expected value of \(y\) when \(x=0\) and \(\beta_1\), the slope gives the expected change in \(y\) for a one-unit increase in \(x\). The error, \(\varepsilon\) is the amount each individual \(y\) differs from the population line (we would not expect all values of \(y\) to fall directly on the line). When we use a sample of data to estimate the true population line, we get our prediction equation or \(\hat{y}=\hat{\beta}_0 + \hat{\beta}_1x\). Residuals from the predicted line is defined as \(e=y-\hat{y}\). Ordinary Least Squares seeks to minimize the sum of squared residuals or sum of squared error. That objective is known as a loss function. The sum of squared error (SSE) or equivalently the mean squared error (MSE) loss functions are by far the most popular loss functions for continuous prediction problems.
We should note that SSE is not the only loss function at our disposal. Minimizing the mean absolute error (MAE) is common in situations with a highly skewed response variable (squaring very large errors gives those observations in the tail too much influence on the regression as we will later discuss). Using MAE to drive our loss function gives us predictions that are conditional medians of the response, given the input data. Other loss functions, like Huber’s M function, are also used to handle problems with influential observations as discussed in Chapter 5.
As we mentioned in Section 2.1, a simple linear regression serves two purposes:
- to predict the expected value of \(y\) for each value of \(x\) and
- to explain how \(y\) is expected to change for a unit change in \(x\).
In order to accurately use a regression for the second purpose, however, we must first meet assumptions with our data.
2.7.1 Assumptions of Linear Regression
Linear regression, in particular the hypothesis tests that are generally performed as part of linear regression, has 4 assumptions:
- The expected value of \(y\) is linear in \(x\) (proper model specification).
- The random errors are independent.
- The random errors are normally distributed.
- The random errors have equal variance (homoskedasticity).
It must now be noted that these assumptions are also in effect for the test of Pearson’s correlation in Section 2.6.1, because the tests in simple linear regression are mathematically equivalent to that test. When these assumptions are not met, another approach to testing the significance of a linear relationship should be considered. The most common non-parametric approach to testing for an association between two continuous variables is Spearman’s correlation. Spearman’s correlation does not limit its findings to linear relationships; any monotonic relationship (one that is always increasing or always decreasing) will cause Spearman’s correlation to be significant. Similar to the approach taken by Kruskal-Wallis, Spearman’s correlation replaces the data with its ranks and computes Pearson’s correlation on the ranks. The same cor and cor.test() functions can be used; simply specify the method='spearman' option.
2.7.2 Testing for Association
The statistical test of correlation is mathematically equivalent to testing the hypothesis that the slope parameter in Equation (2.5) is zero. This t-test is part of the output from any linear regression function, like lm() which we saw in Section 2.4. Let’s confirm this using the example from the Section 2.6.1 where we investigate the relationship between Gr_Liv_Area and Sale_Price. Again, the t-test in the output tests the following hypothesis:
\[H_0: \beta_1=0\]
\[H_a: \beta_1 \neq 0\]
The first thing we will do after creating the linear model is check our assumption using the default plots from lm() . From these four plots we will be most interested in the first two.
In the top left plot, we are visually checking for homoskedasticity. We’d like to see the variability of the points remain constant from left to right on this chart, indicating that the errors have constant variance for each value of y. We do not want to see any fan shapes in this chart. Unfortunately, we do see just that: the variability of the errors is much smaller for smaller values of Sale Price than it is for larger values of Sale Price.
In the top right plot, we are visually checking for normality of errors. We’d like to see the QQ-plot indicate normality with all the points roughly following the line. Unfortunately, we do not see that here. The errors do not appear to be normally distributed.
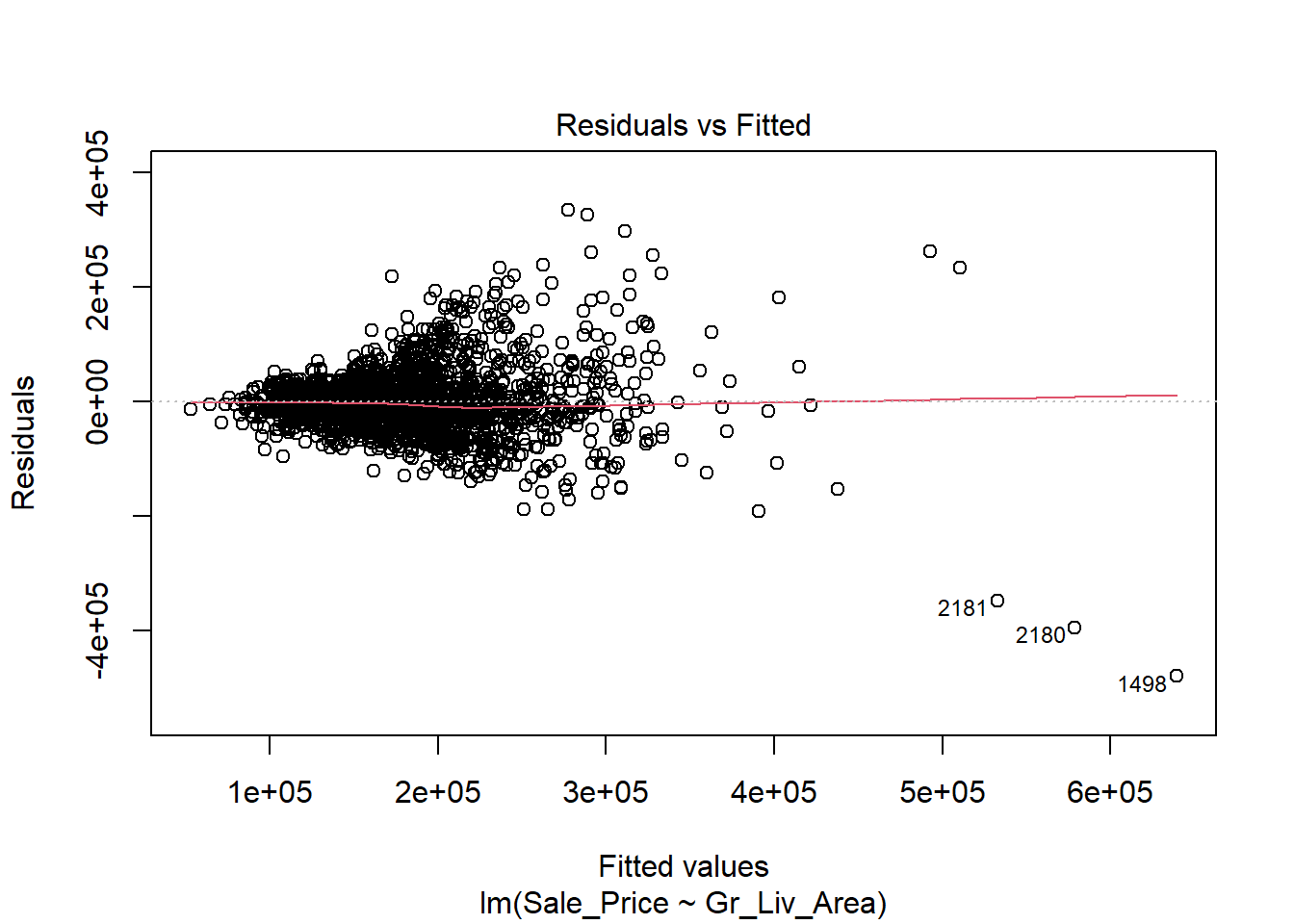
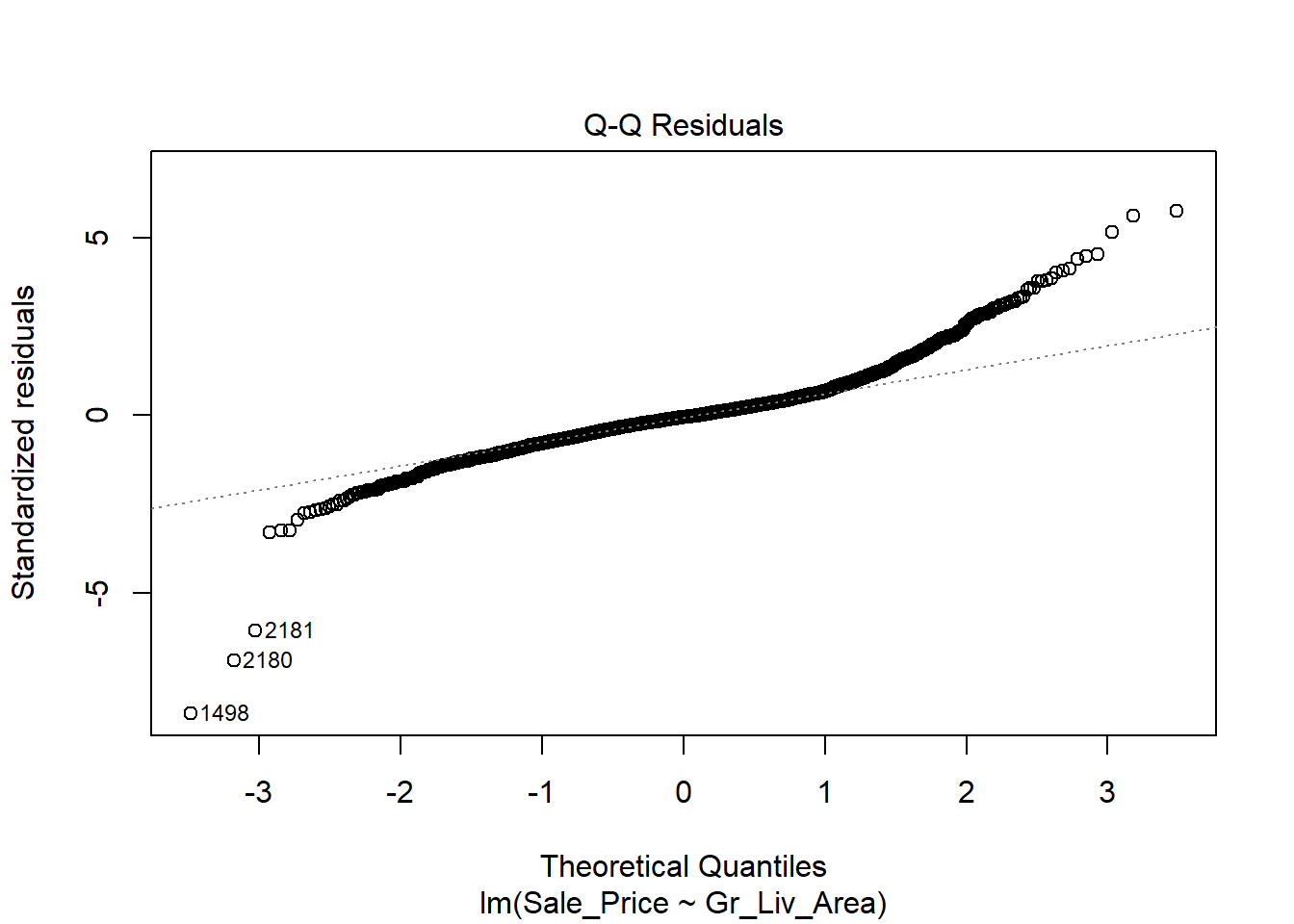
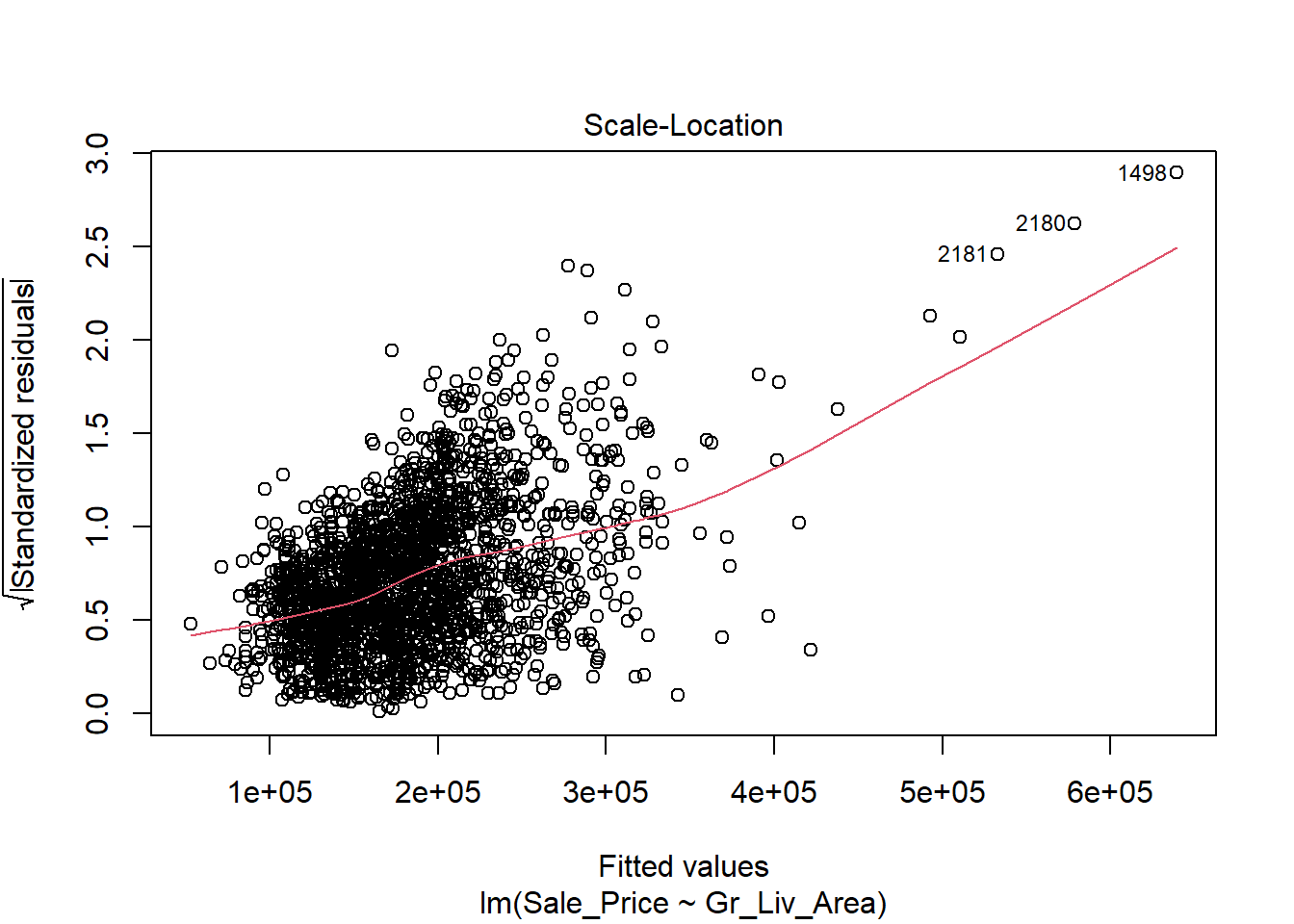
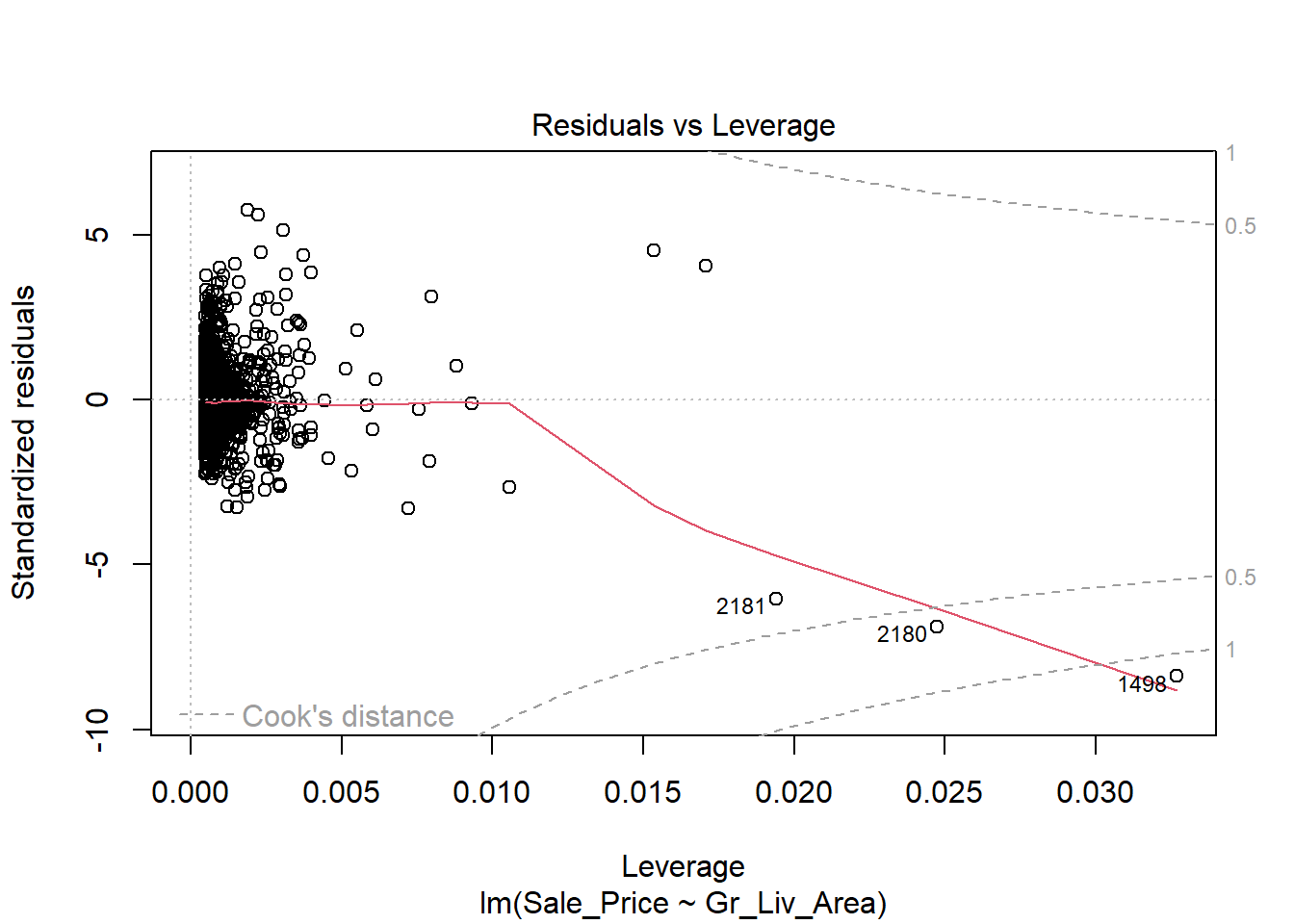
Despite the violation of assumptions, let’s continue examining the output from this regression in order to practice our interpretation of it.
##
## Call:
## lm(formula = Sale_Price ~ Gr_Liv_Area, data = train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -479466 -30364 -2855 22635 334558
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 15770.153 4006.043 3.937 8.54e-05 ***
## Gr_Liv_Area 110.545 2.521 43.857 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 58110 on 2049 degrees of freedom
## Multiple R-squared: 0.4842, Adjusted R-squared: 0.4839
## F-statistic: 1923 on 1 and 2049 DF, p-value: < 2.2e-16The first thing we’re likely to examine in the coefficient table is the p-value for Gr_Liv_Area. It is strongly significant (in fact, it’s the same t-value and p-value as we saw for the cor.test as these tests are mathematically equivalent), indicating that there is an association between the size of the home and the sale price. Furthermore, the parameter estimate is 110.73 indicating that we’d expect the price of a home to increase by $110.73 for every additional square foot of living space. Because of the linearity of the model, we can extend this slope estimate to any unit change in \(x\). For example, it might be difficult to think in terms of single square feet when comparing houses, so we might prefer to use a 100 square-foot change and report our conclusion as follows: For each additional 100 square feet of living area, we expect the house price to increase by $11,0726.
If we want to do this for a categorical variable with two levels (for example with Central Air), we would use the following code:
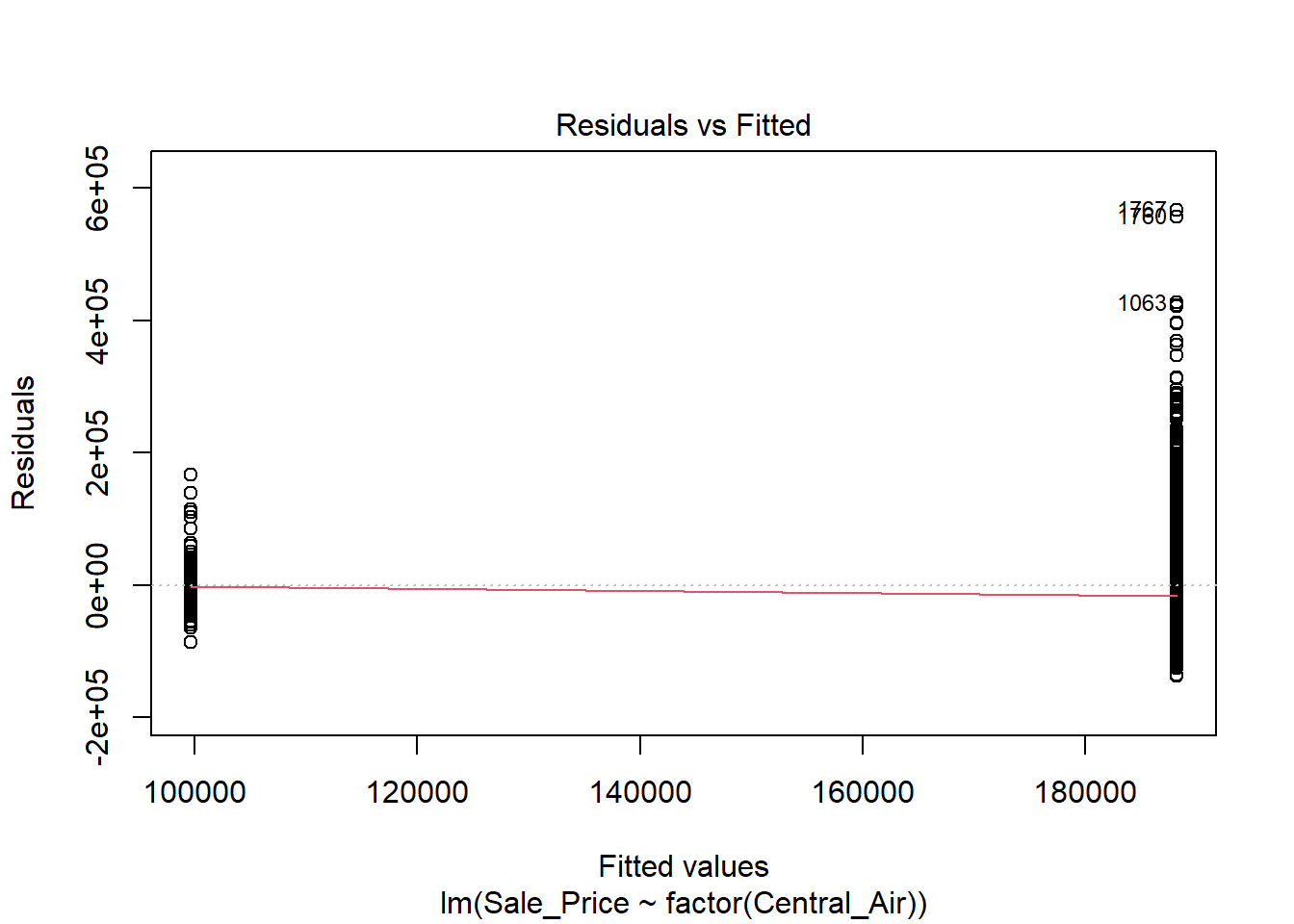
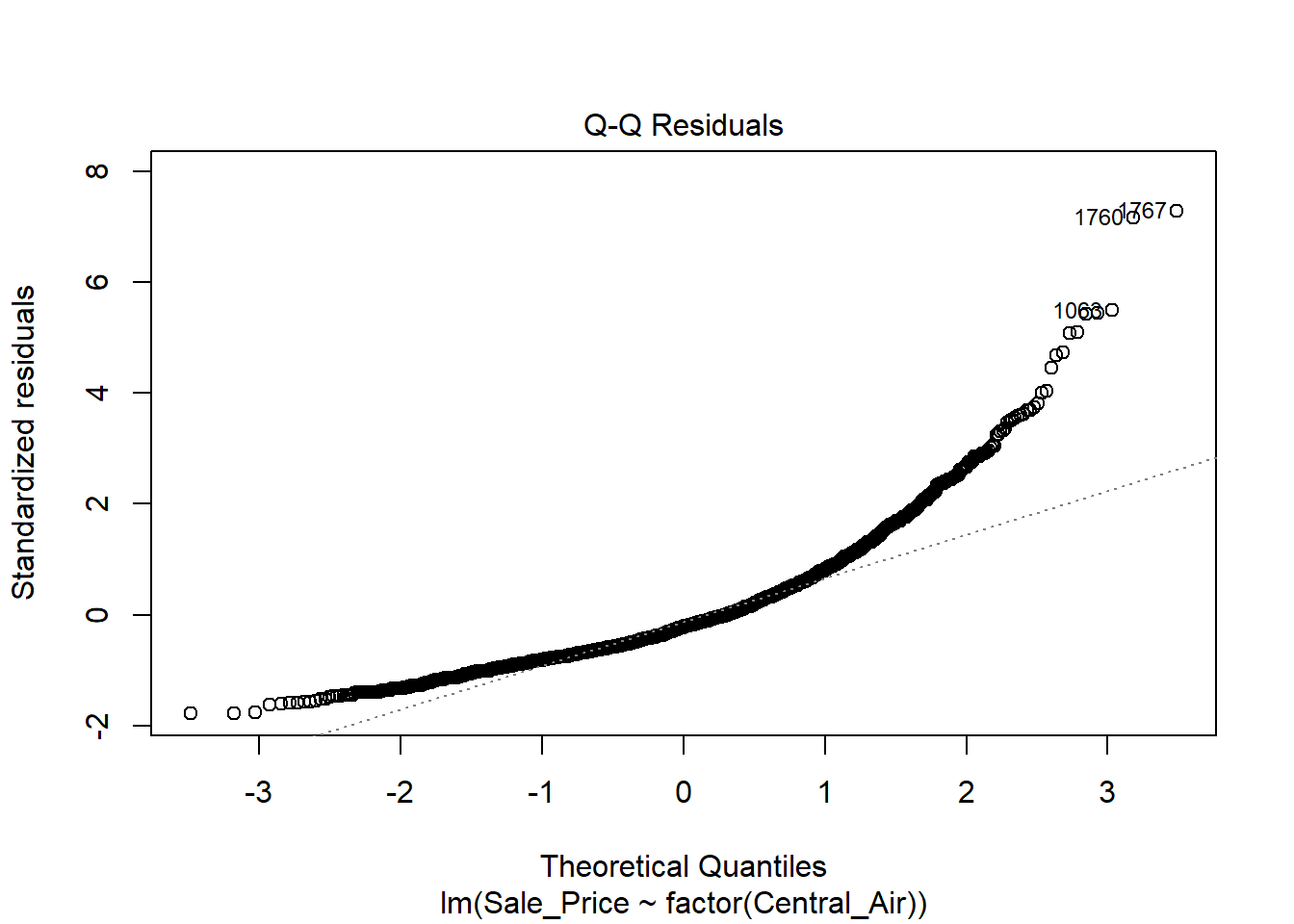
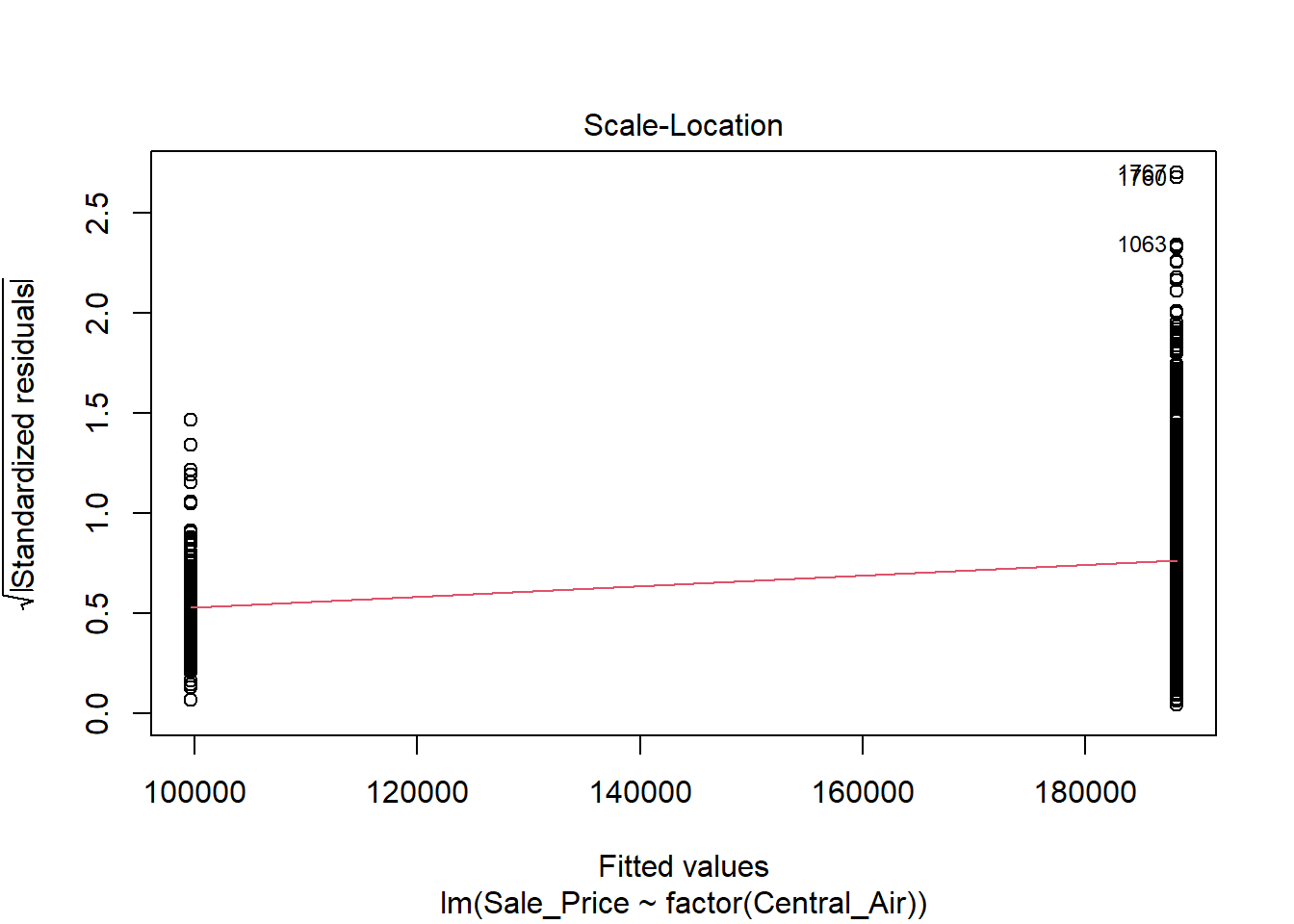
The variance does NOT look constant and Normality is not a good assumption here. However, just for illustration purposes, here is the output:
##
## Call:
## lm(formula = Sale_Price ~ factor(Central_Air), data = train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -138164 -51164 -16264 31336 566836
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 99645 6623 15.04 <2e-16 ***
## factor(Central_Air)Y 88519 6858 12.91 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 77800 on 2049 degrees of freedom
## Multiple R-squared: 0.0752, Adjusted R-squared: 0.07475
## F-statistic: 166.6 on 1 and 2049 DF, p-value: < 2.2e-16We see that Central does indeed have a significant linear relationship with Sales Price. Looking at the above output, we see that X took on the value of 1 if the category was “Yes” and 0 if it was “No”. Therefore, we can interpret the coefficient as we expect the sales price of a home in Ames, Iowa to be on average $83,938 higher if they have central air compared to those homes that do not have central air.
2.7.3 Python Code
Assumptions of Linear Regression
## SignificanceResult(statistic=0.719959092874937, pvalue=0.0)Fit linear regression:
## <class 'statsmodels.iolib.summary.Summary'>
## """
## OLS Regression Results
## ==============================================================================
## Dep. Variable: Sale_Price R-squared: 0.484
## Model: OLS Adj. R-squared: 0.484
## Method: Least Squares F-statistic: 1923.
## Date: Tue, 24 Jun 2025 Prob (F-statistic): 6.98e-297
## Time: 08:24:10 Log-Likelihood: -25409.
## No. Observations: 2051 AIC: 5.082e+04
## Df Residuals: 2049 BIC: 5.083e+04
## Df Model: 1
## Covariance Type: nonrobust
## ===============================================================================
## coef std err t P>|t| [0.025 0.975]
## -------------------------------------------------------------------------------
## Intercept 1.577e+04 4006.043 3.937 0.000 7913.812 2.36e+04
## Gr_Liv_Area 110.5452 2.521 43.857 0.000 105.602 115.488
## ==============================================================================
## Omnibus: 342.298 Durbin-Watson: 2.050
## Prob(Omnibus): 0.000 Jarque-Bera (JB): 4078.850
## Skew: 0.396 Prob(JB): 0.00
## Kurtosis: 9.863 Cond. No. 4.96e+03
## ==============================================================================
##
## Notes:
## [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
## [2] The condition number is large, 4.96e+03. This might indicate that there are
## strong multicollinearity or other numerical problems.
## """Look at Normality
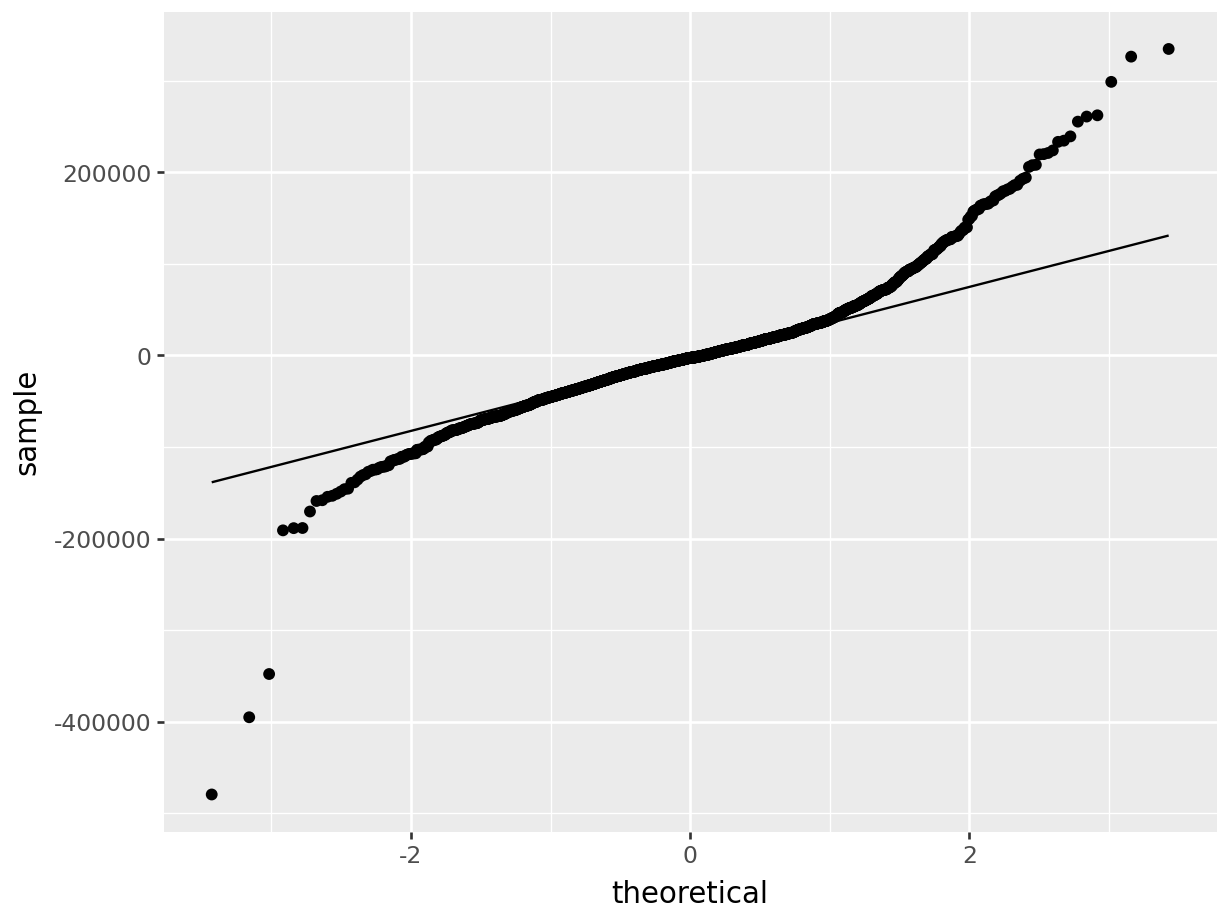
Residual plot:
p = (
ggplot(train, aes(x='pred_slr',y='resid_slr'))+ geom_point()+ labs(x='Predicted Values',y='Residuals')
)
p.show()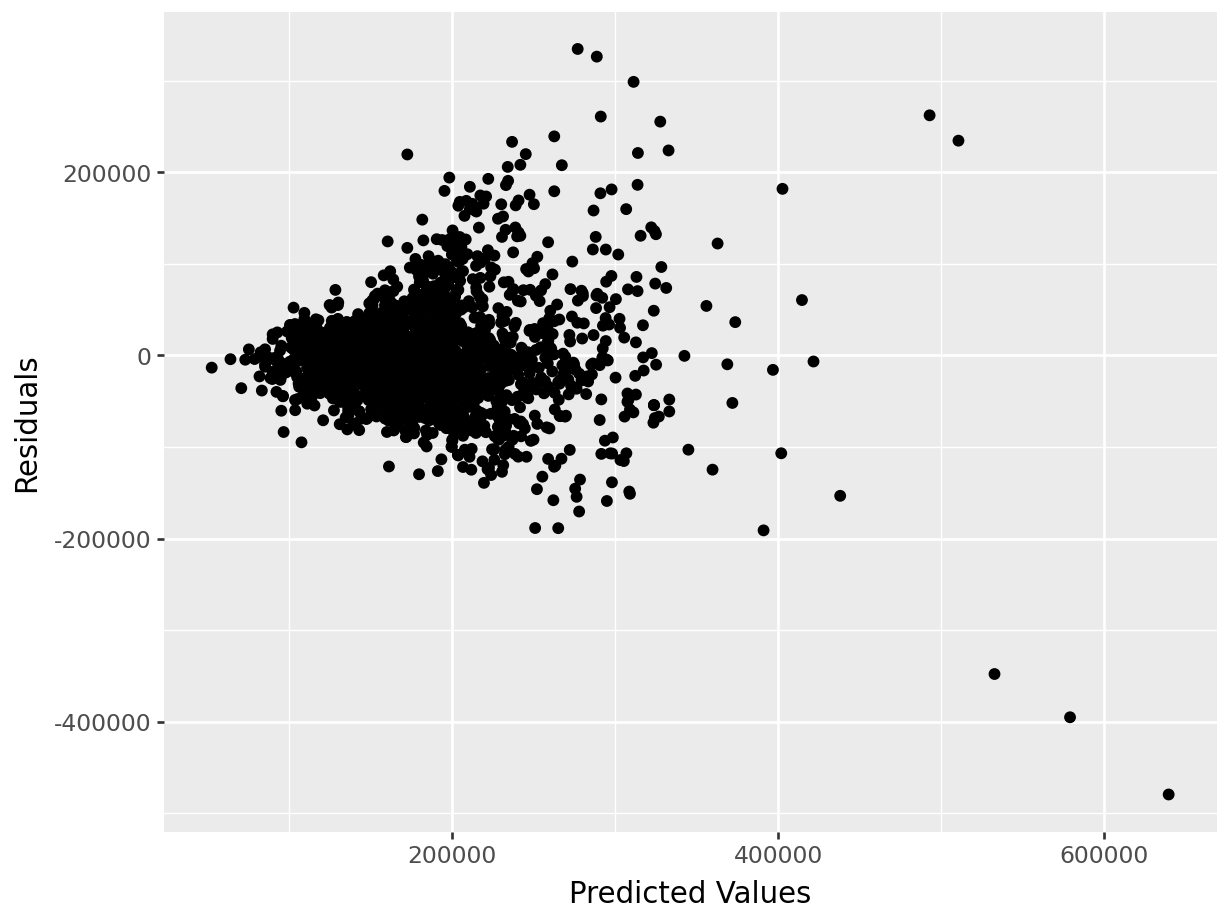
With categorical variable:
## <class 'statsmodels.iolib.summary.Summary'>
## """
## OLS Regression Results
## ==============================================================================
## Dep. Variable: Sale_Price R-squared: 0.075
## Model: OLS Adj. R-squared: 0.075
## Method: Least Squares F-statistic: 166.6
## Date: Tue, 24 Jun 2025 Prob (F-statistic): 1.05e-36
## Time: 08:24:11 Log-Likelihood: -26008.
## No. Observations: 2051 AIC: 5.202e+04
## Df Residuals: 2049 BIC: 5.203e+04
## Df Model: 1
## Covariance Type: nonrobust
## =======================================================================================
## coef std err t P>|t| [0.025 0.975]
## ---------------------------------------------------------------------------------------
## Intercept 9.965e+04 6623.194 15.045 0.000 8.67e+04 1.13e+05
## C(Central_Air)[T.Y] 8.852e+04 6857.927 12.908 0.000 7.51e+04 1.02e+05
## ==============================================================================
## Omnibus: 816.452 Durbin-Watson: 2.040
## Prob(Omnibus): 0.000 Jarque-Bera (JB): 4081.413
## Skew: 1.840 Prob(JB): 0.00
## Kurtosis: 8.850 Cond. No. 7.58
## ==============================================================================
##
## Notes:
## [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
## """Plots:
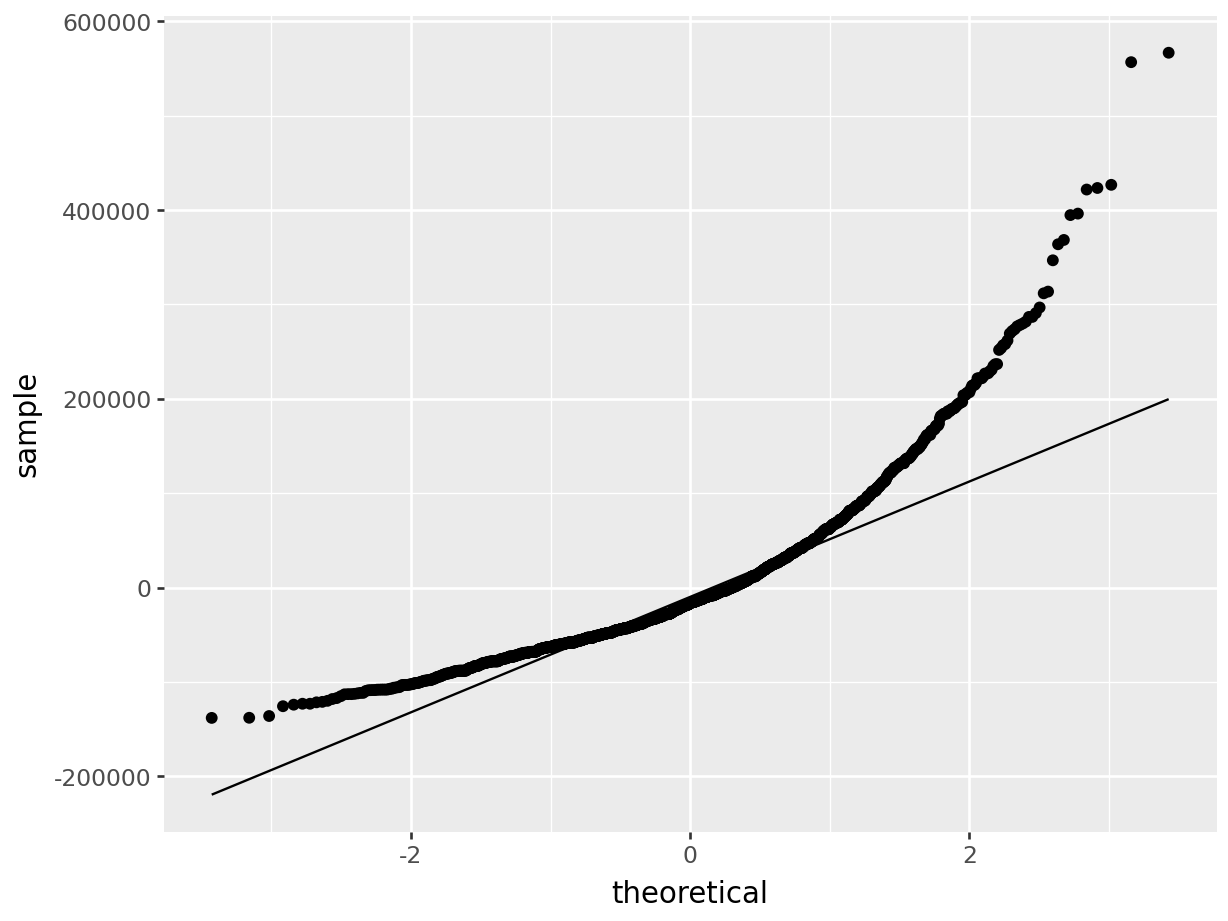
p = (
ggplot(train, aes(x='pred_slr',y='resid_slr'))+ geom_point()+ labs(x='Predicted Values',y='Residuals')
)
p.show()
The n-dimensional “variable vectors” and live in the vast sample space where the \(i^{th}\) axis represents the \(i^th\) observation in your dataset. In this space, a single point/vector is one possible set of sample values of n observations; this space can be difficult to grasp mentally↩︎